580 California St., Suite 400
San Francisco, CA, 94104
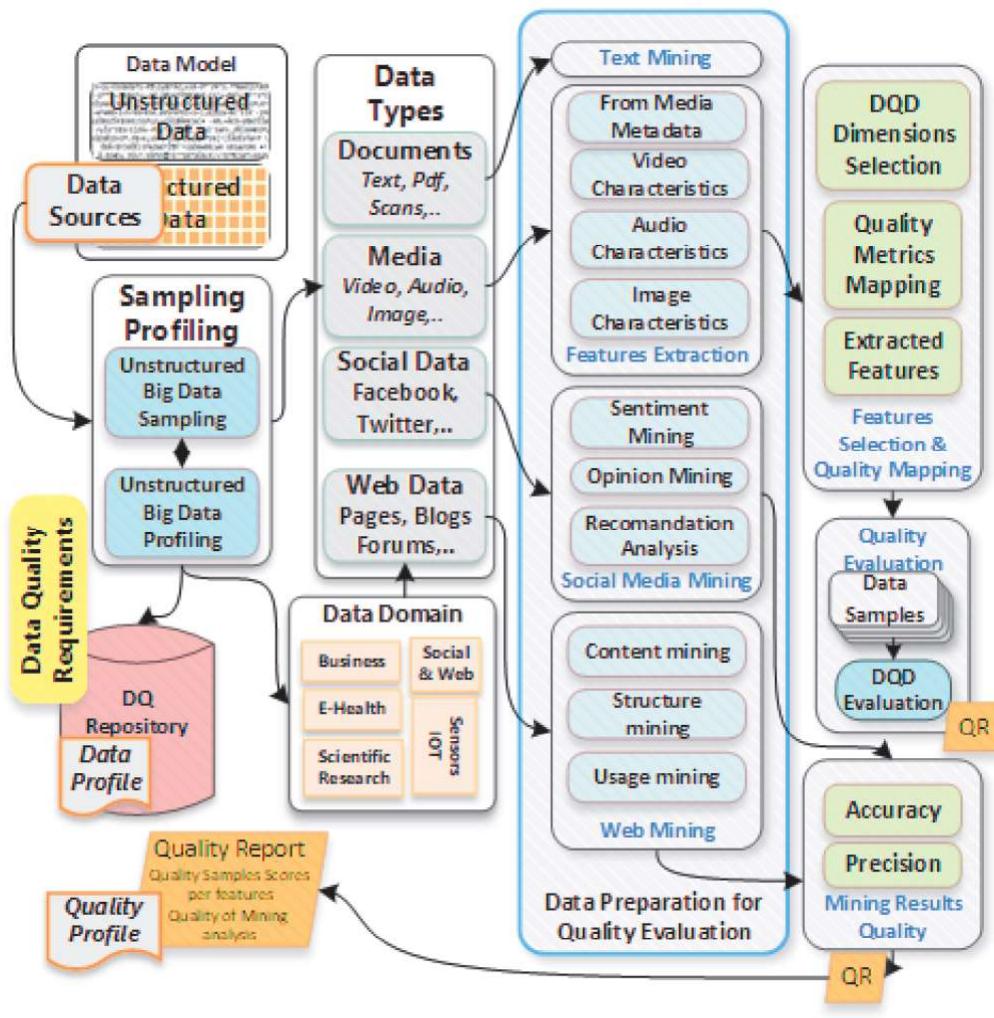
This theme investigates preprocessing challenges inherent in unstructured data and explores techniques to enhance data quality and understanding prior to analysis. Preprocessing is crucial due to the issues of missing data, outliers, varied granularity, and incomplete records that unstructured datasets frequently present. Optimizing preprocessing strategies impacts the accuracy and reliability of downstream analytics and extraction processes.
This research theme focuses on advanced techniques for extracting meaningful information, associations, and semantic structures from large volumes of unstructured text data. It addresses challenges including natural language processing, text mining, knowledge graph construction, entity recognition, and the use of ontologies to represent complex, heterogeneous data, which are pivotal for enabling effective analytics, prediction, and domain-specific insights from unstructured corpora.
This theme explores methods to collect, process, and analyze large-scale unstructured data originating from social media and web platforms, specifically targeting applications such as customer service analytics, disaster management, and business intelligence. Key concerns include data capture strategies, text mining challenges, integration with structured data, and extraction of actionable insights at scale for domain-specific decision support.