580 California St., Suite 400
San Francisco, CA, 94104
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser.
1998, … of the 1998 conference of the …
https://doi.org/10.1145/783160.783184…
12 pages
1 file
AI
This research presents a novel framework for mining multimedia data, focusing on the concept of locales characterized by visual features. The framework encompasses techniques for color localization, feature extraction, and resolution refinement, addressing challenges such as the non-disjoint nature of locales and the importance of recurrent items in visual datasets. It further discusses traditional algorithms like Apriori, and proposes a progressive resolution refinement strategy for efficient multimedia data mining.












icde, 2000
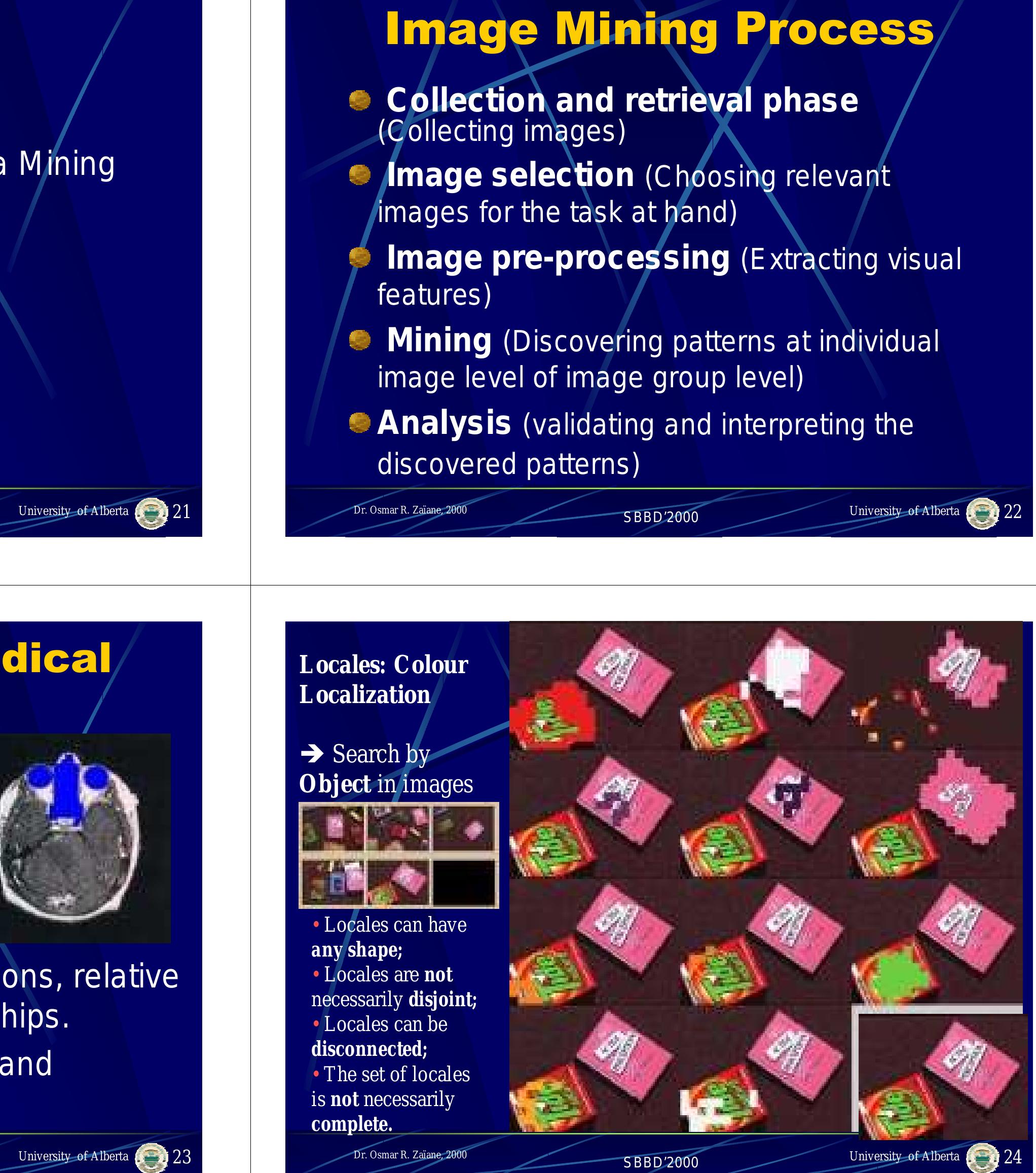
Despite the overwhelming amounts of multimedia data recently generated and the significance of such data, very few people have systematically investigated multimedia data mining. With our previous studies on content-based retrieval of visual artifacts, we study in this paper the methods for mining content-based associations with recurrent items and with spatial relationships from large visual data repositories. A progressive resolution refinement approach is proposed in which frequent item-sets at rough resolution levels are mined, and progressively, finer resolutions are mined only on the candidate frequent item-sets derived from mining rough resolution levels. Such a multi-resolution mining strategy substantially reduces the overall data mining cost without loss of the quality and completeness of the results.
Knowledge and Information Systems, 2006
Generating captions or annotations automatically for still images is a challenging task. Traditionally, techniques involving higher-level (semantic) object detection and complex feature extraction have been employed for scene understanding. On the basis of this understanding, corresponding text descriptions are generated for a given image. In this paper, we pose the auto-annotation problem as that of multi-relational association rule mining where the relations exist between image-based features, and textual annotations. The central idea is to combine low-level image features such as color, orientation, intensity, etc. and corresponding text annotations to generate association rules across multiple tables using multi-relational association mining. Subsequently, we use these association rules to auto-annotate test images. In this paper we also present a multi-relational extension to the FP-tree algorithm to accomplish the association rule mining task effectively. The motivation for using multi-relational association rule mining for multimedia data mining is to exhibit the potential accorded by multiple descriptions for the same image (such as multiple people labeling the same image differently). Moreover, multi-relational association rule mining can also benefit the auto-annotation process by pruning the number of trivial associations that are generated if text and image features were combined in a single table through a join. In this paper, we discuss these issues and the results of our auto-annotation experiments on different test sets. Another contribution of this paper is highlighting a need to develop robust evaluation metrics for the image annotation task. We propose several applicable scoring techniques and then evaluate the performance of the different algorithms to study the utility of these techniques. A detailed analysis of the datasets used and the performance results are presented to conclude the paper.
2004
This paper presents algorithms for finding the meanings of the audio-visual video patterns obtained in the unsupervised discovery process. This problem is interesting in domains where neither perceptual patterns nor semantic concepts have simple structures. The patterns in the video are modeled with hierarchical hidden Markov models, with efficient algorithms to jointly learn the model parameters, the optimal model complexity, as well as the relevant feature subsets. The meanings are contained in words of the speech transcript of the video. The pattern-word association is obtained via co-occurrence analysis and machine translation models. Promising results are obtained on TRECVID news videos: video patterns that associate with distinct topics such as el-nino and politics are itentified; a temporal structure model compares favorably to a non-temporal clustering algorithm.
Semantic Mining Technologies for Multimedia Databases, 2009
ASSOCIATION RULES IMPLEMENTATION FOR AFFINITY ANALYSIS BETWEEN ELEMENTS COMPOSING MULTIMEDIA OBJECTS, 2019
The multimedia objects are a constantly growing resource in the world wide web, consequently it has generated as a necessity the design of methods and tools that allow to obtain new knowledge from the information analyzed. Association rules are a technique of Data Mining, whose purpose is to search for correlations between elements of a collection of data (data) as support for decision making from the identification and analysis of these correlations. Using algorithms such as: A priori, Frequent Parent Growth, QFP Algorithm, CBA, CMAR, CPAR, among others. On the other hand, multimedia applications today require the processing of unstructured data provided by multimedia objects, which are made up of text, images, audio and videos. For the storage, processing and management of multimedia objects, solutions have been generated that allow efficient search of data of interest to the end user, considering that the semantics of a multimedia object must be expressed by all the elements that composed of. In this article an analysis of the state of the art in relation to the implementation of the Association Rules in the processing of Multimedia objects is made, in addition the analysis of the consulted literature allows to generate questions about the possibility of generating a method of association rules for the analysis of these objects.
IJCSNS, 2010
Over the past decades, data mining has proved to be a successful approach for extracting hidden knowledge from huge collections of structured digital data stored in databases. From the inception, Data mining was done primarily on numerical set of data. Nowadays as large multimedia data sets such as audio, speech, text, web, image, video and combinations of several types are becoming increasingly available and are almost unstructured or semistructured data by nature, which makes it difficult for human beings to extract the information without powerful tools. This drives the need to develop data mining techniques that can work on all kinds of data such as documents, images, and signals. This paper explores on survey of the current state of multimedia data mining and knowledge discovery, data mining efforts aimed at multimedia data, current approaches and well known techniques for mining multimedia data.
2009 IEEE International Conference on Semantic Computing, 2009
Association rule mining (ARM) has been studied in the areas of content-based multimedia retrieval and semantic concept detection due to its high efficiency and accuracy. Two important processes in mining the association rules for classification are rule generation and rule selection. In this paper, a novel high-level feature detection framework using the ARM technique together with the correlations among the feature-value pairs is proposed. A new association rule mining (ARM) algorithm has been developed, where the N -featurevalue pairs are generated using a combined measure based on (1) the existence of the (N -1)-feature-value pairs (where N is larger than 1), (2) the correlation between different Nfeature-value pairs and the concept classes through Multiple Correspondence Analysis (MCA), and (3) the similarity representing the harmonic mean of the inter-similarity and intrasimilarity. The final association classification rules are selected by using the calculated harmonic mean of the similarity values. The proposed framework enables the automatic discovery and generation of the N -feature-value pair association rules from the 1-feature-value pairs for classification. Experimenting with 15 high-level features (concepts) and benchmark data sets from TRECVID, our proposed framework achieves promising performance and outperforms three other wellknown classifiers (Decision Trees, Support Vector Machine, and Neural Networks) which are commonly used for performance comparison in the TRECVID community.
2007 IEEE 11th International Conference on Computer Vision, 2007
We present a novel approach to automatically find spatial configurations of local features occurring frequently on instances of a given object class, and rarely on the background. The approach is based on computationally efficient data mining techniques and can find frequent configurations among tens of thousands of candidates within seconds. Based on the mined configurations we develop a method to select features which have high probability of lying on previously unseen instances of the object class. The technique is meant as an intermediate processing layer to filter the large amount of clutter features returned by lowlevel feature extraction, and hence to facilitate the tasks of higher-level processing stages such as object detection.
Multimedia data mining is a popular research domain which helps to extract interesting knowledge from multimedia data sets such as audio, video, images, graphics, speech, text and combination of several types of data sets. Normally, multimedia data are categorized into unstructured and semi-structured data. These data are stored in multimedia databases and multimedia mining is used to find useful information from large multimedia database system by using various multimedia techniques and powerful tools. This paper provides the basic concepts of multimedia mining and its essential characteristics. Multimedia mining architectures for structured and unstructured data, research issues in multimedia mining, data mining models used for multimedia mining and applications are also discussed in this paper. It helps the researchers to get the knowledge about how to do their research in the field of multimedia mining.
Data Mining and Knowledge Discovery: Theory, Tools, and Technology III, 2001

Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
EURASIP Journal on Advances in Signal Processing, 2006
Welcome to the special issue on "Information mining from multimedia databases." The main focus of this issue is on information mining techniques for the extraction and interpretation of semantic contents in multimedia databases. The advances in multimedia production technologies have resulted in a rapid proliferation of various forms of media data types on the Internet. Given these high volumes of multimedia data, it is thus essential to extract and interpret their underlying semantic contents from the original signal-based representations without the need for extensive user interaction, and the technique of multimedia information mining plays an important role in this automatic content interpretation process.
Lecture Notes in Computer Science, 2003
The primary aim of this research project is to develop a generic framework and methodologies that will enable the augmentation of expert knowledge with knowledge extracted from multimedia sources such as text and pictures, for the purpose of classification and analysis. For evaluation and testing purposes of this research study, a furniture design style domain is selected because it is a common belief that design style is an intangible concept that is difficult to analyze. In this paper, we present the results of the analysis of keywords in the text descriptions of design styles. A simple keyword-based matching technique is used for classification and domain specific dictionaries of keywords are used to reduce the dimensionality of feature space. A comparative evaluation was carried out for this classifier and SVM and decision tree based classifier C4.5
MDM/KDD, 2000
An electronic version of the proceedings will be archived after the workshop at the ACM digital library archive site: http://www.acm.org/sigkdd/proceedings/mdmkdd00/ iv v Foreword Multimedia computing, especially networked multimedia, in science, business, academia, medicine and government generates substantial amount of digital media data sets. Vinton G. Cerf, President of the Internet Society and Senior Vice-President of MCI Data Services compares the activities surrounding multimedia ideas with the metaphor of a disturbed ant hill, in which the inhabitants run hither and yon to discover the cause of disturbance and, perhaps, to do something about it. No wonder researchers and developers in multimedia information systems turn to data mining and knowledge discovery methods looking for techniques for improving the indexing and retrieval of necessary information out of these data sets. Furthermore, as the ultimate goal of the knowledge discovery process is turning data into knowledge, there is a need for methods, techniques and tools that on the one hand, extract patterns from such divergent data sets and transform them into useful information and knowledge, and, on the other hand, provide consistent framework for incorporation and use of discovered knowledge in the information systems.
Journal of Big Data
In recent years, due to information technology such as a computer, Internet, software and the development of sensor technology, make present life appeared "everything can be a digital", big data is becoming a hot research topic in the field of all kinds of industrial [1]. Big Data has been created in the fields of business applications such as marketing, social networking, science, and smartphone applications. Nowadays, better computing power is more necessary in the area of data mining [2]. Image comparison is largely used in different fields: shape matching [3], registration [4]. However, comparing binary images that represent the same content is not easy because an image can undergo transformations like rotation, translation, resolution change. In data mining, there are many frequent patterns (FP) mining algorithms e.g FP-growth [5], CFP-growth [6], MISFP-growth (Multiple Item Support Frequent Patterns) [7], Apriori [8]. A comparison of FP mining algorithms is given in [9]. Apriori algorithm is the best-known basic algorithm proposed by R. Agrawal and R. Srikant in 1994. The Apriori algorithm is one of the most important algorithms which is used to retrieve frequent itemsets. For large databases, there exists the algorithms FTWeight-edHashT [10] and MISFP-growth [9]. It essentially requires two important things: minimum support and minimum confidence [11, 12]. Most of the commonly used association rule discovery algorithm that utilise the frequent itemset strategy, and which is exemplified by the Apriori algorithm [13]. The Apriori algorithm searches
2019
Nowadays, multimedia technology is widely applied in everywhere. Data quarrying or mining is an effective and powerful approach for extracting hidden information from enormous collections of synchronized digital data stored in databases. In digital library Data mining is the key technology. It is required to retrieve the information of text and manage and also retrieve the video information. Multimedia Data Mining is the technique to be used to discover the implicit, effective, valuable and intelligible pattern from a large amount of multimedia data by analyzing the feature of seeing and hearing and then to discover knowledge and obtain the tendency and association among the events. And it can also provide us the ability of decision supporting to resolve the problem. This paper discusses the basic theories of Data Mining and its current approaches.
2002
Foreword Since the beginning of the century there have been two successful international workshops on multimedia data mining at the KDD forums: MDM/KDD2000 and MDM/KDD2001, in conjunction with KDD2000 (in Boston) and KDD2001 (in San Francisco), respectively. These workshops brought together numerous experts in spatial data analysis, digital media, multimedia information retrieval, state-of-art data mining and knowledge discovery in multimedia database systems, analysis of data in collaborative virtual environments. For more information about the workshops see the reports on the workshops in SIGKDD Explorations (2 (2), pp. 103-105 and 3 (2), pp. 65-67, respectively). Participants in both workshops were pleased with the event and there was consensus about the necessity of turning it into an annual meeting, where researchers, both from the academia and industry can exchange and compare both relatively mature and green house theories, methodologies, algorithms and frameworks for multime...
2005
Image mining [1] deals with extraction of implicit knowledge, image data relationship or other patterns not explicitly stored in images and uses ideas from computer vision, image processing, image retrieval, data mining, machine learning, databases and AI. The fundamental challenge in image mining is to determine how low-level, pixel
Conference Multimedia and Expo, 2004. ICME'04. 2004 IEEE International Conference on Volume 2 Pages 1299-1302 Publisher IEEE, 2004
The administration of very large collections of images accentuates the classical problems of indexing and eBciently querying information. This paper describes a new method applied to very large still image databases that combines two data mining techniques: clustering and association rules mining in order to better organize image collections and to improve the performance of queries. The objective of our work is to exploit association rules discovered by mining global MPEG-7 features data and to adapt the query processing. In our experiment, we use five MPEG-7 features to describe several thousands of still images. For each feature, we initially determine several clusters of images by using a K-mean algorithm. Then. we generate association rules between different clusters of features and exploit these rules to rewrite !he query and to optimize the query-bycontent processing.
International Journal of Science Technology & Engineering
Recently, many video mining approaches have been proposed which can be roughly classified into five categories. They are: video pattern mining, video clustering and classification, video association mining, video content structure mining, and video motion mining. In this paper I’m addressing the video association mining approach. This approach is relatively new and emerging research trend. It consists of two key phases are (i) Video Pre-processing and (ii) Frequent Temporal Pattern mining. The first phase converts the original input video to a sequence format. The second phase concerns the generation of frequent patterns. I have done survey on the previous papers that are discovering associations in a given video.
2004
We examine the significance of video mining as pattern discovery in multimedia content. We examine the underlying issue of pattern discovery versus pattern recognition, since most past work has not drawn such a sharp distinction. We argue that while the termpattern discoveryïmplies a purely unsupervised approach, in practice a mixture of unsupervised and supervised techniques will have to be used. We compare conventional data mining with video mining and observe that a key difference is in the multi-layered semantics of multimedia content. We then identify significant challenges posed by video mining.