{kind=link}
580 California St., Suite 400
San Francisco, CA, 94104

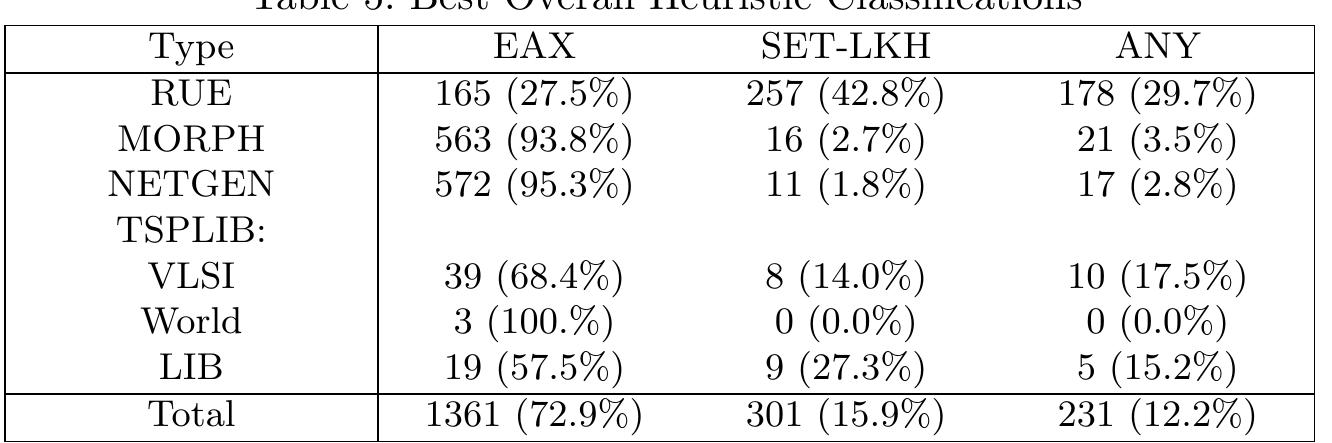
Figure 5 It is important to be able to identify instance features which can inform specific algorithm selection. To this end, a decision tree model was trained using the Pihera and TSPMETA feature sets described earlier. A decision tree is a simple but useful technique for creating “rules of thumb ” that can be applied to identify instance traits that may hamper the performance of specific solvers. This process identified key features (and their associated values) which can be used to select the most effective instance-specific algorithms. From the head of the decision tree shown in Fig. 5, two key features were extracted which can be used to identify a significant variance in performance between the EAX and SET-LKH solvers: nn5.sc.max.n, from the Pihera feature set; and mst_dists_median, from the TSPMETA feature set. It can be seen that 72% of instances were solved significantly faster by EAX than either of the SET-LKH heuristics and, in a further 16%, no significan difference was found (cf. Table 5 & Fig. 5(a)). The intuitive choice, therefore would be to use EAX by default; however, note that 12% of all instances testec were best solved by the SET-LKH heuristics. It was found that 67% of all in stances exhibited nn5.sc.max.n < 0.71; of these, 93% were solved best by EAX (cf. Figures 5(b) and 6(a)). When nn5.sc.max.n >= 0.71, 71% were solved by SET-LKH heuristics in comparable (29%) or less (42%) time, Fig. 5(c).