{kind=link}
580 California St., Suite 400
San Francisco, CA, 94104

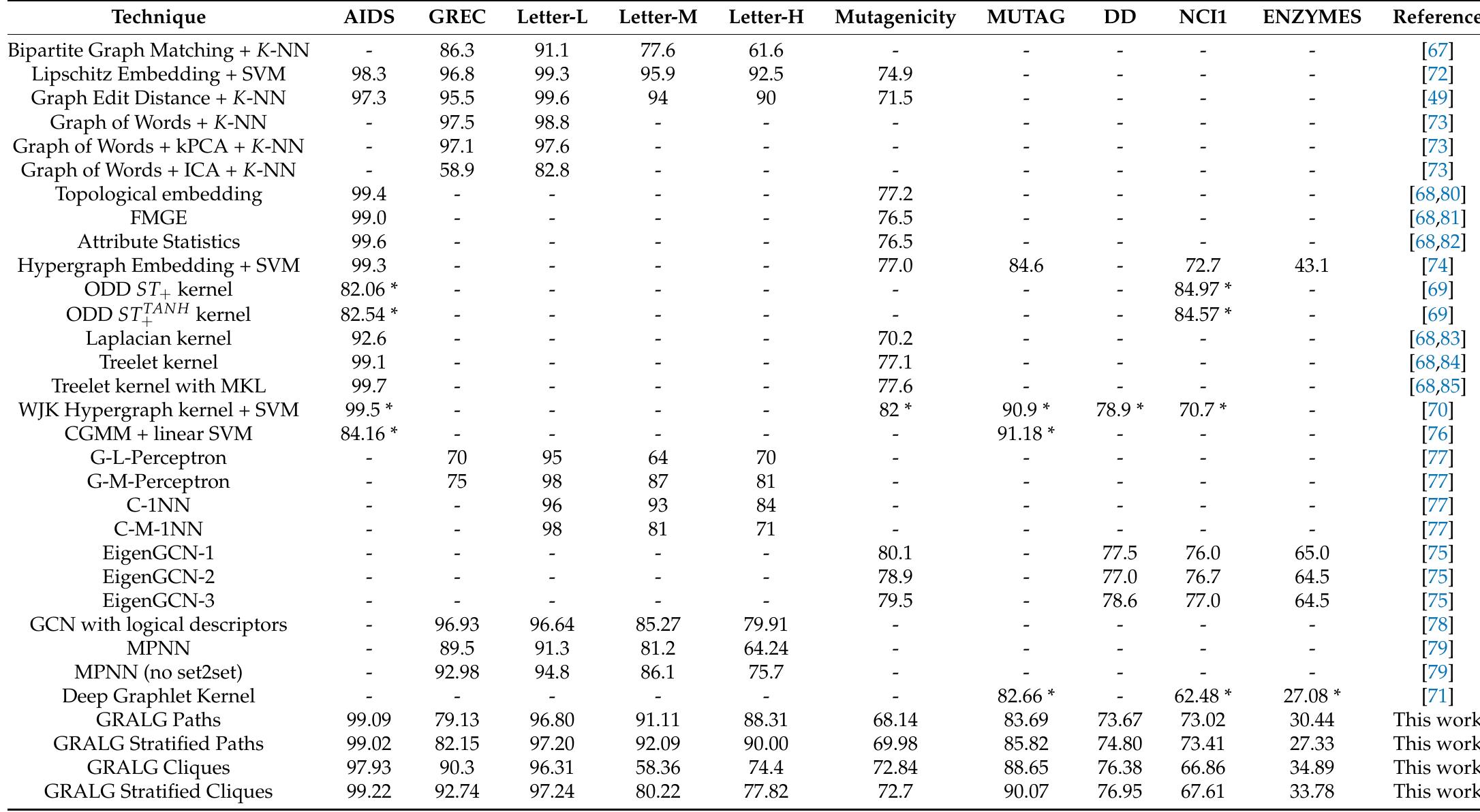
Figure 2 ENZYMES emerges as the only dataset showing the same phenomenon. By looking at the magnitude of the accuracy boost, cliques seem to benefit more from a stratified granulation approach: indeed, the vast majority of the boosts in terms of accuracy are upper-bounded oy 10%, whereas the majority of path-based granulators reach at most a 3% accuracy boost Nith respect to the non-stratified counterpart. By looking at Figure 2, we can observe the number of symbols (i.e., the size of the alphabet) after the second genetic-driven feature selection stage. In principle, a clique- based approach is likely to yield a smaller alphabet: this is due to the fact that an n- vertex graph can have at most 0(3"/%) cliques, whereas the number of paths can grow as O(n!) in the worst case, so the set of prospective information granules (even without any subsampling) is smaller. Conversely to the accuracy case, a stratified approach does not necessarily yield benefits. As can be seen in the breakdown (Figure 4), as paths are concerned, the stratification yields a smaller alphabet for 4 datasets out of 10. As cliques are concerned, the same phenomenon happens for 3 out of 10 datasets. This phenomenon is particularly evident for binary classification problems: a clear sign that building two dedicate alphabets (one for the positive class, one for the negative class) is excessive and just one alphabet would be a smarter choice.