 Liwei Ren
Liwei Ren580 California St., Suite 400
San Francisco, CA, 94104
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser.
…
29 pages
1 file
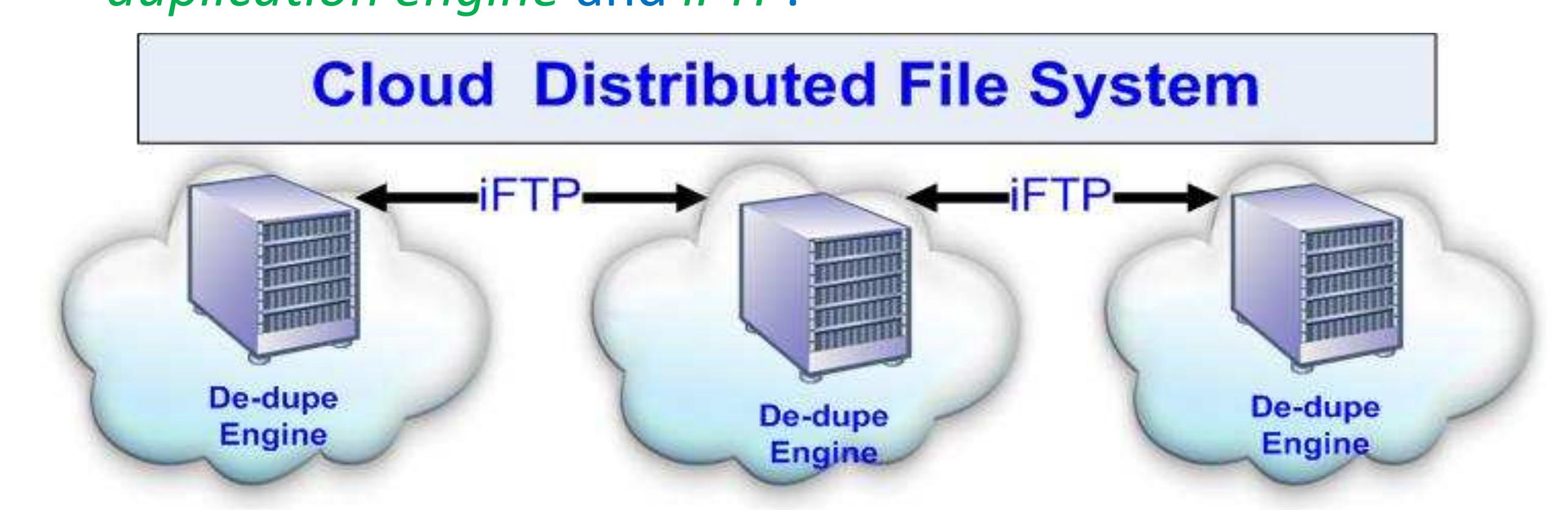
It talks about three technologies for big data. (a) Data de-duplication to reduce cloud storage cost; (b) File Sync Protocols to reduce traffic between clouds & between users and clouds; (c) High speed file transport protocols.
AI









Advances in data mining and database management book series, 2018
Cloud Computing is a new computing model that distributes the computation on a resource pool. The need for a scalable database capable of expanding to accommodate growth has increased with the growing data in web world. More familiar Cloud Computing vendors such as Amazon Web Services, Microsoft, Google, IBM and Rackspace offer cloud based Hadoop and NoSQL database platforms to process Big Data applications. Variety of services are available that run on top of cloud platforms freeing users from the need to deploy their own systems. Nowadays, integrating Big Data and various cloud deployment models is major concern for Internet companies especially software and data services vendors that are just getting started themselves. This chapter proposes an efficient architecture for integration with comprehensive capabilities including real time and bulk data movement, bi-directional replication, metadata management, high performance transformation, data services and data quality for customer and product domains.
International journal of scientific and research publications, 2022
Big Data is emerging technology era implicates to handle huge amount of data to store, retrieve, manage, analyzed and processing. Big Data handles data like structured , semi structured and unstructured data for different applications like Ecommerce, Hospital, HealthCare, Social Media, Cloud Computing, IOT based and many more. for storage, management and processing different tools are required to handle such peta and tera bytes amount of data. Traditional tools was not unable to perform management and analysis of complex, semi-structured ,and unstructured data. Big Data has different tools to handle, managed, querying different categories of mainly unstructured and semi-structured data using like Cassandra, Spark, Hadoop, Map-Reduce, Couch DB, Mongo DB and many more tools helping out developers to perform different operations on it.
Technology transfer: fundamental principles and innovative technical solutions
Big Data has been created from virtually everything around us at all times. Every digital media interaction generates data, from computer browsing and online retail to iTunes shopping and Facebook likes. This data is captured from multiple sources, with terrifying speed, volume and variety. But in order to extract substantial value from them, one must possess the optimal processing power, the appropriate analysis tools and, of course, the corresponding skills. The range of data collected by businesses today is almost unreal. According to IBM, more than 2.5 times four million data bytes generated per year, while the amount of data generated increases at such an astonishing rate that 90 % of it has been generated in just the last two years. Big Data have recently attracted substantial interest from both academics and practitioners. Big Data Analytics (BDA) is increasingly becoming a trending practice that many organizations are adopting with the purpose of constructing valuable inform...
Journal of Grid Computing, 2018
Big Data represents a major challenge for the performance of the cloud computing storage systems. Some distributed file systems (DFS) are widely used to store big data, such as Hadoop Distributed File System (HDFS), Google File System (GFS) 1 0 and others. These DFS replicate and store data as multiple copies to provide availability and reliability, but they increase storage and resources consumption.
IJSRCSEIT, 2019
The major objective of this paper is to present Big Data Storage techniques and Data Virtualization. The Data virtualization servers have focused on making big data processing easy. They can hide the complex and technical interfaces of big data storage technologies, such as Hadoop and NoSQL, and they can present big data as if it is stored in traditional SQL systems. This allows us as developers to use our own existing skills and to deploy our traditional ETL, reporting, and analytical tools that all support SQL. Additionally, the products and our existing skills can extend the data security mechanisms for accessing and processing big data across multiple big data systems. But with scale and performance rising, making big data processing is not enough and easy anymore. As such, the next challenge for data virtualization is parallel to big data processing. In this paper, All of the above regular issues are covered in my paper along with their proper prospects.
International Journal of Computer Applications, 2015
Today, in order to support decision for strategic advantages alignment, companies' have started to realize the importance of using large data. It is being observed through different study cases that "Large data usually demands for faster processing". As a result, companies are now investing more in processing larger sets of data rather than investing in expensive algorithms. A larger amount of data gives a better inference for decision making but also working with it can create challenge due to processing limitations. In order to easily manage and use this large amount of content in a proper systematic manner, Big Data, HDFS & other file systems were being introduced.
Future Generation Computer Systems, 2019
Big Data represents a major challenge for the performance of the cloud computing storage systems. Some distributed file systems (DFS) are widely used to store big data, such as Hadoop Distributed File System (HDFS), Google File System (GFS) 1 and others. These DFS replicate and store data as multiple copies to provide availability and reliability, but they increase storage and resources consumption. In a previous work (Kaseb, Khafagy, Ali, & Saad, 2018), we built a Redundant Independent Files (RIF) system over a cloud provider (CP), called CPRIF, which provides HDFS without replica, to improve the overall performance through reducing storage space, resources consumption, operational costs and improved the writing and reading performance. 1 However, RIF suffers from limited availability, limited reliability and increased data recovery time. In this paper, we overcome the limitations of the RIF system by giving more chances to recover a lost block (availability) and the ability of the system to keep working the presence of a lost block (reliability) with less computation (time overhead). As well as keeping the benefits of storage and resources consumption attained by RIF compared to other systems. We call this technique "High Availability Redundant Independent Files" (HARIF), which is built over CP; called CPHARIF. 2 According to the experimental results of the HARIF system using the TeraGen benchmark, it is found that the execution time of recovering data, availability and reliability using HARIF have been improved as compared with RIF. Also, the stored data size and resources consumption with HARIF system is reduced compared to the other systems. The Big Data storage is saved and the data writing and reading are improved.
2016
In the current scenario, big data is the biggest challenge for the industries to deal with. It is characterized by Huge Volume, Heterogeneous unidentified sources, High rate of data generation, inability to extract value information from irrelevant data. There are many approaches been put forward for dealing with this Big Data, some of them are RDBMS, Hadoop, Cloud Computing etc. This review article includes an elicitation of definitions of Big Data from some previous work, its characteristics, applications, various implementation techniques proposed for dealing with Big Data. It also discusses about some of the benchmarks which are proposed by companies.

Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
Frontiers of Information Technology & Electronic Engineering, 2017
There is a great thrust in industry toward the development of more feasible and viable tools for storing fast-growing volume, velocity, and diversity of data, termed 'big data'. The structural shift of the storage mechanism from traditional data management systems to NoSQL technology is due to the intention of fulfilling big data storage requirements. However, the available big data storage technologies are inefficient to provide consistent, scalable, and available solutions for continuously growing heterogeneous data. Storage is the preliminary process of big data analytics for real-world applications such as scientific experiments, healthcare, social networks, and e-business. So far, Amazon, Google, and Apache are some of the industry standards in providing big data storage solutions, yet the literature does not report an in-depth survey of storage technologies available for big data, investigating the performance and magnitude gains of these technologies. The primary objective of this paper is to conduct a comprehensive investigation of state-of-the-art storage technologies available for big data. A well-defined taxonomy of big data storage technologies is presented to assist data analysts and researchers in understanding and selecting a storage mechanism that better fits their needs. To evaluate the performance of different storage architectures, we compare and analyze the existing approaches using Brewer's CAP theorem. The significance and applications of storage technologies and support to other categories are discussed. Several future research challenges are highlighted with the intention to expedite the deployment of a reliable and scalable storage system.
Big Data must be processed with advanced collection and analysis tools, based on predetermined algorithms, in order to obtain relevant information. Algorithms must also take into account invisible aspects for direct perceptions. Big Data issues is multi-layered. A distributed parallel architecture distributes data on multiple servers (parallel execution environments) thus dramatically improving data processing speeds. Big Data provides an infrastructure that allows for highlighting uncertainties, performance, and availability of components. DOI: 10.13140/RG.2.2.12784.00004
:Due to the advent of new technologies, devices, and communication means like social networking sites, the amount of data produced by mankind is growing rapidly every year. The amount of data produced by us from the beginning of time till 2003 was 5 billion gigabytes. If you pile up the data in the form of disks it may fill an entire football field. The same amount was created in every two days in 2011, and in every ten minutes in 2013. However, this rate is still growing enormously. Though all this information produced is meaningful and can be useful when processed, it is being neglected.
Advances in Science, Technology and Engineering Systems Journal
These last years, the amount of data generated by information systems has exploded. It is not only the quantities of information that are now estimated in Exabyte, but also the variety of these data which is more and more structurally heterogeneous and the velocity of generation of these data which can be compared in many cases to endless flows. Now days, Big Data science offers many opportunities to analyze and explore these quantities of data. Therefore, we can collect and parse data, make many distributed operations, aggregate results, make reports and synthesis. To allow all these operations, Big Data Science relies on the use of "Distributed File Systems (DFS)" technologies to store data more efficiently. Distributed File Systems were designed to address a set of technological challenges like consistency and availability of data, scalability of environments, competitive access to data or even more the cost of their maintenance and extension. In this paper, we attempt to highlight some of these systems. Some are proprietary such as Google GFS and IBM GPFS, and others are open source such as HDFS, Blobseer and AFS. Our goal is to make a comparative analysis of the main technological bricks that often form the backbone of any DFS system.
2020
Big Data make conversant with novel technology, skills and processes to your information architecture and the people that operate, design, and utilization them. The big data delineate a holistic information management contrivance that comprise and integrates numerous new types of data and data management together conventional data. The Hadoop is an unlocked source software framework licensed under the Apache Software Foundation, render for supporting data profound applications running on huge grids and clusters, to proffer scalable, credible, and distributed computing. This is invented to scale up from single servers to thousands of machines, every proposition local computation and storage. In this paper, we have endeavored to converse about on the taxonomy for big data and Hadoop technology. Eventually, the big data technologies are necessary in providing more actual analysis, which may leadership to more concrete decision-making consequence in greater operational capacity, cost de...
Journal of Energy and Power Engineering, 2016
In recent years, due to the widespread use of electronic services and the use of social network as well, large volumes of information are being made that this information contains various types of things such as videos, photos, texts etc. besides large volume. Due to the high volume and the lack of specificity of this information, covering them through traditional and relational databases is not possible and modern solutions should be used for processing them, so that processing speed is also covered. Data storage for processing and the way of accessing to them in memory, network communication, covering required features for distributed system in solutions that are in use for storing big data, are the items that should be covered. In this paper, a collection of advantages and challenges of big data, special features and characteristics of them has been provided and with the introduction of technologies in use, storage methods are studied and research opportunities to continue the way will be introduced.
International Journal of Fog Computing, 2019
Computing systems are becoming increasingly data-intensive because of the explosion of data and the needs for processing the data, and subsequently storage management is critical to application performance in such data-intensive computing systems. However, if existing resource management frameworks in these systems lack the support for storage management, this would cause unpredictable performance degradation when applications are under input/output (I/O) contention. Storage management of data-intensive systems is a challenge. Big Data plays a most major role in storage systems for data-intensive computing. This article deals with these difficulties along with discussion of High Performance Computing (HPC) systems, background for storage systems for data-intensive applications, storage patterns and storage mechanisms for Big Data, the Top 10 Cloud Storage Systems for data-intensive computing in today's world, and the interface between Big Data Intensive Storage and Cloud/Fog Com...
ArXiv, 2020
From home appliances to industrial enterprises, the \emph{Information and Communication Technology (ICT)} industry is revolutionizing the world. We are witnessing the emergence of new technologies (e.g, Cloud computing, Fog computing, Internet of Things (IoT), Artificial Intelligence (AI) and Block-chain) which proves the growing use of ICT (e,g. business, education, health, and home appliances), resulting in massive data generation. It is expected that more than 175 ZB data will be processed annually by 75 billion devices by 2025. The \emph{5G technology} (i.e. mobile communication technology) dramatically increases network speed, enabling users to upload ultra high definition videos in real-time, which will generate a massive stream of big data. Furthermore, smart devices, having artificial intelligence, will act like a human being (e.g, a self-driving vehicle, etc) on the network, will also generate big data. This sudden shift and massive data generation created serious challenge...
International Journal of Communication Systems, 2014
Advanced communication systems for enhanced big data technology and applications
International Journal of Innovative Research in Computer Science & Technology, 2021
With the advent of new emerging technologies like fog computing, internet of things, blockchain, artificial intelligence etc, information and communication technology is revolutionising our homes, education, health and industry. By the year 2025, with the increase in network speed offered by 5G technology, we will be able to share much more data in real time. It's not only important to note that the volume of data shared in future will be huge but also its important to understand that the shared data will be heterogenous in nature. Not only humans but smart devices will act as humans on the network and will generate big data. Thus, the future of cloud storage industry seems to be very bright. The effort in this paper is to recognise the issues and challenges that the cloud storage industry will face in the near future and also to identify and review the new paradigm for researchers in the field of cloud storage.