 Hencil Peter
Hencil Peter580 California St., Suite 400
San Francisco, CA, 94104
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser.
2010, International Journal of Computer Applications
https://doi.org/10.5120/1102-1445…
6 pages
1 file
The DBSCAN [1] algorithm is a popular algorithm in Data Mining field as it has the ability to mine the noiseless arbitrary shape Clusters in an elegant way. As the original DBSCAN algorithm uses the distance measures to compute the distance between objects, it consumes so much processing time and its computation complexity comes as O (N 2). In this paper we have proposed a new algorithm to improve the performance of DBSCAN algorithm. The existing algorithms A Fast DBSCAN Algorithm[6] and Memory effect in DBSCAN algorithm[7] has been combined in the new solution to speed up the performance as well as improve the quality of the output. As the RegionQuery operation takes long time to process the objects, only few objects are considered for the expansion and the remaining missed border objects are handled differently during the cluster expansion. Eventually the performance analysis and the cluster output show that the proposed solution is better to the existing algorithms.
AI
The proposed algorithm reduces RegionQuery calls and includes four selected seed objects for cluster expansion, enhancing performance particularly in border areas.
LongRegionQuery retrieves objects within Eps and 2*Eps distances, while ShortRegionQuery focuses exclusively on fewer objects, dramatically speeding up processing times.
Lemma 2 demonstrates that four circles can adequately cover all immediate neighbours of a core object, improving the accuracy of cluster expansions by minimizing missed objects.
Non-core objects are designated as noise during processing, yet the new algorithm ensures comprehensive inclusion of border objects, reducing overlooked potential clusters.
Empirical data indicates a performance increase of approximately 20% in cluster coverage without sacrificing accuracy compared to the original DBSCAN.
International Journal for Research in Applied Science & Engineering Technology (IJRASET), 2022
Clustering is a form of learning by observations. It is an unsupervised learning method and does not require training data set to generate a model. Clustering can lead to the discovery of previously unknown groups within the data. It is a common method of data mining in which similar and dissimilar type of data would be clustered into different clusters for better analysis of the data. In this paper the DBSCAN algorithm has been applied to compute the EPS value and Euclidian distance on the basis of similarity or dissimilarity of the input data. Also back propagation algorithm is applied to calculate Euclidian distance dynamically and simulation study is conducted that shows improvement to increase accuracy and reduce execution time.
2016
Clustering is a primary and vital part in data mining. Density based clustering approach is one of the important technique in data mining. The groups that are designed depending on the density are flexible to understand and do not restrict itself to the outlines of clusters. DBSCAN Algorithm is one of the density grounded clustering approach which is employed in this paper. The author addressed two drawbacks of DBSCAN algorithm i.e. determination of Epsilon value and Minimum number of points and further proposed a novel efficient DBSCAN algorithm as to overcome this drawback. This proposed approach is introduced mainly for the applications on images as to segment the images very efficiently depending on the clustering algorithm. The experimental results of the suggested approached showed that the noise is highly reduced from the image and segmentations of the images are also improved better compared to the existing image segmentation approaches.
International journal of engineering research and technology, 2018
While data containing any type of information is getting ubiquitous, proper processing of such data is very much obliged. To classify spatial data, various clustering algorithms have been invented. DBSCAN (Density Based Spatial Clustering of Application with Noise) is one of the consummate clustering algorithm with respect to discovery of arbitrarily shaped cluster in a spatial datasets. Due to its flexibility and tremendous research potential, DBSCAN algorithm is one of the most cited in scholarly literature. Considering the fact that most researchers tried to experiment and evaluate the algorithm, certain modifications of DBSCAN were made in order to have more efficient outcomes or to reduce time complexities. This paper discusses such modified algorithms and how they surpass the original DBSCAN in certain ways. Thorough analysis of each algorithm is mentioned and their critical evaluation is done accordingly. These algorithms are then comparatively evaluated with regards to various parameters.
2012
One of the main categories in Data Clustering is density based clustering. Density based clustering techniques like DBSCAN are attractive because they can find arbitrary shaped clusters along with noisy outlier. The main weakness of the traditional density based algorithms like DBSCAN is clustering the different density level data sets. DBSCAN calculations done according to given parameters applied to all points in a data set, while densities of the data set clusters may be totally different. The proposed algorithm overcomes this weakness of the traditional density based algorithms. The algorithm starts with partitioning the data within a cluster to units based on a user parameter and compute the density for each unit separately. Consequently, the algorithm compares the results and merges neighboring units with closer approximate density values to become a new cluster. The experimental results of the simulation show that the proposed algorithm gives good results in finding clusters for different density cluster data set.
18th International Conference on Pattern Recognition (ICPR'06), 2006
Density based clustering techniques like DBSCAN can find arbitrary shaped clusters along with noisy outliers. A severe drawback of the method is its huge time requirement which makes it a unsuitable one for large data sets. One solution is to apply DBSCAN using only a few selected prototypes. But because of this the clustering result can deviate from that which uses the full data set. A novel method proposed in the paper is to use two types of prototypes, one at a coarser level meant to reduce the time requirement, and the other at a finer level meant to reduce the deviation of the result. Prototypes are derived using leaders clustering method. The proposed hybrid clustering method called l-DBSCAN is analyzed and experimentally compared with DBSCAN which shows that it could be a suitable one for large data sets.
International Journal of Computer Applications, 2013
Clustering is a primary method for DB mining. The clustering process becomes very challenge when the data is different densities, different sizes, different shapes, or has noise and outlier. Many existing algorithms are designed to find clusters. But, these algorithms lack to discover clusters of different shapes, densities and sizes. This paper presents a new algorithm called DBCLUM which is an extension of DBSCAN to discover clusters based on density. DBSCAN can discover clusters with arbitrary shapes. But, fail to discover different-density clusters or adjacent clusters. DBCLUM is developed to overcome these problems. DBCLUM discovers clusters individually then merges them if they are density similar and joined. By this concept, DBCLUM can discover different-densities clusters and adjacent clusters. Experiments revealed that DBCLUM is able to discover adjacent clusters and different-densities clusters and DBCLUM is faster than DBSCAN with speed up ranges from 11% to 52%.
IJCSMC, 2019
The data mining is the approach which extracts useful information from the rough information. The clustering is the approach of data mining which cluster the similar and dissimilar type of information. The clustering techniques is of various type which hierarchal clustering, density based clustering and so on. The DBSCAN algorithm is the density based clustering algorithm. The density based clustering has the various algorithms. In this research work, clustering techniques related to density based clustering is reviewed and analyzed in terms of certain parameters.
2013
Cluster detection in Spatial Databases is an important task for discovery of knowledge in sp atial databases and in this domain density based clusteri ng algorithms are very effective. Density Based Spa tial Clustering of Applications with Noise (DBSCAN) algo rithm effectively manages to detect clusters of arb itrary shape with noise, but it fails in detecting local c lusters as well as clusters of different density pr esent in close proximity. Density Differentiated Spatial Clusterin g (DDSC) and Local-Density Based Spatial Clustering Algorithm with Noise (LDBSCAN) manage to detect clu sters of different density as well as local cluster s very effectively, but the number of input parameters is very high. Here I have proposed a new density based clustering algorithm with the introduction of a con cept called Cluster Constant which basically repres ents the uniformity of distribution of points in a cluster. In order to find the density of a point I have used new measure called Reacha...
International Journal of Computer Applications, 2011
This paper presents a comparative study of three Density based Clustering Algorithms that are DENCLUE, DBCLASD and DBSCAN. Six parameters are considered for their comparison. Result is supported by firm experimental evaluation. This analysis helps in finding the appropriate density based clustering algorithm in variant situations.
The tremendous amount of data produced now a days in various application domains such as molecular biology or geography can only be fully exploited by efficient and effective data mining tools. One of the primary data mining tasks is clustering, which is the task of partitioning points of a data set into distinct groups (clusters) such that two points from one cluster are similar to each other whereas two points from distinct clusters are not. The detection of clusters in a given dataset is important for data analysis. This paper presents a possible DBSCAN clustering algorithm implementation. DBSCAN algorithm is based on density reachable and density connected point. Adding distributed SR-tree technique to density clustering algorithm we can improve clustering results.
J. Hencil Peter
Department of Computer Science
St. Xavier’s College, Palayamkottai, India
The DBSCAN [1] algorithm is a popular algorithm in Data Mining field as it has the ability to mine the noiseless arbitrary shape Clusters in an elegant way. As the original DBSCAN algorithm uses the distance measures to compute the distance between objects, it consumes so much processing time and its computation complexity comes as O(N2). In this paper we have proposed a new algorithm to improve the performance of DBSCAN algorithm. The existing algorithms A Fast DBSCAN Algorithm[6] and Memory effect in DBSCAN algorithm[7] has been combined in the new solution to speed up the performance as well as improve the quality of the output. As the RegionQuery operation takes long time to process the objects, only few objects are considered for the expansion and the remaining missed border objects are handled differently during the cluster expansion. Eventually the performance analysis and the cluster output show that the proposed solution is better to the existing algorithms.
Optimised DBSCAN, Density Cluster, Optimised RegionQuery, RegionQuery.
Data mining is a fast growing field in which clustering plays a very important role. Clustering is the process of grouping a set of physical or abstract objects into classes of similar objects [2]. Among the many algorithms proposed in the clustering field, DBSCAN is one of the most popular algorithms due to its high quality of noiseless output clusters. As the original DBSCAN algorithm RegionQuery function is very expensive factor in terms of time, we have proposed a solution to minimize the RegionQuery function call to cover the maximum neighbours in an elegant way. The Fast DBSCAN Algorithm’s[6] seleted seed objects’ RegionQuery has been improved to give the better output, at the same time within less time using Memory effect in DBSCAN algorithm[7]. The remaining objects present in the border area have been examined separately during the cluster expansion which is not done in the Fast DBSCAN Algorithm. So the new algorithm is capable to give the better performance than the existing DBSCAN algorithms.
Rest of the paper is organised as follows. Section 2 gives the brief history about the related works in the same area. Section 3 gives the introduction of original DBSCAN and section 4 explains the proposed algorithm. After the new algorithm’s explanation, section 5 shows the Experimental Results and final section 6 presents the conclusion and future work associated with this algorithm.
The DBSCAN (Density Based Spatial Clustering of Application with Noise) [1] is the basic clustering algorithm to mine the clusters based on objects density. In this algorithm, first the number of objects present within the neighbour region (Eps) is computed. If the neighbour objects count is below the given threshold value, the object will be marked as NOISE. Otherwise
the new cluster will be formed from the core object by finding the group of density connected objects that are maximal w.r.t densityreachability.
The CHAMELEON [3] is a two phase algorithm. It generates a k-nearest graph in the first phase and hierarchical cluster algorithm has been used in the second phase to find the cluster by combining the sub clusters.
The OPTICS [4] algorithm adopts the original DBSCAN algorithm to deal with variance density clusters. This algorithm computes an ordering of the objects based on the reachability distance for representing the intrinsic hierarchical clustering structure. The Valleys in the plot indicate the clusters. But the input parameters ξ is critical for identifying the valleys as ξ clusters.
The DENCLUE [5] algorithm uses kernel density estimation. The result of density function gives the local density maxima value and this local density value is used to form the clusters. If the local density value is very small, the objects of clusters will be discarded as NOISE.
A Fast DBSCAN (FDBSCAN) Algorithm[6] has been invented to improve the speed of the original DBSCAN algorithm and the performance improvement has been achieved through considering only few selected representative objects belongs inside a core object’s neighbour region as seed objects for the further expansion. Hence this algorithm is faster than the basic version of DBSCAN algorithm and suffers with the loss of result accuracy.
The MEDBSCAN [7] algorithm has been proposed recently to improve the performance of DBSCAN algorithm, at the same time without loosing the result accuracy. In this algorithm totally three queues have been used, the first queue will store the neighbours of the core object which belong inside Eps distance, the second queue is used to store the neighbours of the core object which belong inside 2∗ Eps distance and the third queue is the seeds queue which store the unhandled objects for further expansion. This algorithm guarantees some notable performance improvement if Eps value is not very sensitive.
Though the DBSCAN algorithm’s complexity can be reduced to O(N∗log N) using some spatial trees, it is an extra effort to construct, organize the tree and the tree requires an additional memory to hold the objects. In this new algorithm we have achieved good performance with original computation complexity O(N2).
In the following definitions, a database D with set of points of k dimensional space S has been used. As we need to find out the object neighbours which are exist/surrounded with in the given radius (Eps), Euclidean function dist (p, q) has been used, where p and q are the two objects. This function takes two objects and gives the distance between them.
Definition 1: Eps Neighbourhood of an object p
The Eps Neighbourhood of an object p is referred as NEps(p), defined as
NEps(p)={q∈D∣dist(p,q)<< Eps }
Definition 2: Core Object Condition
An Object p is referred as core object, if the neighbour objects count >= given threshold value (MinObjs).
i.e. ∣NEps(p)∣>=MinObjs
Where MinObjs refers the minimum number of neighbour objects to satisfy the core object condition. In the above case, if p has neighbours which are exist within the Eps radius count is >= MinObjs, p can be referred as core object.
Definition 3: Directly Density Reachable Object
An Object p is referred as directly density reachable from another object q w.r.t Eps and MinObjs if
p∈NEps(q) and
∣NEps(q)∣>=MinObjs (Core Object condition)
Definition 4: Density Reachable Object
An object p is referred as density reachable from another object q w.r.t Eps and MinObjs if there is a chain of objects p1,…,pn, p1=q,pn=p such that pi+1 is directly density reachable from pi.
Definition 5: Density connected object
An Object p is density connected to another object q if there is an object o such that both, p and q are density reachable from o w.r.t Eps and MinObjs.
A Cluster C is a non-empty subset of a Database D w.r.t Eps and MinObjs which satisfying the following conditions.
For every p and q , if p∈ cluster C and q is density reachable from p w.r.t Eps and MinObjs then q∈C.
For every p and q,q∈C;p is density connected to q w.r.t Eps and MinObjs.
An object which doesn’t belong to any cluster is called noise.
The DBSCAN algorithm finds the Eps Neighbourhood of each object in a Database during the clustering process. Before the cluster expansion, if the algorithm finds any non core object, it will be marked as NOISE. With a core object, algorithm initiate a cluster and surrounding objects will be added into the queue for the further expansion. Each queue objects will be popped out and find the Eps neighbour objects for the popped out object. When the new object is a core object, all its neighbour objects will be assigned with the current cluster id and its unprocessed neighbour objects will be pushed into queue for further processing. This process will be repeated until there is no object in the queue for the further processing.
A new algorithm has been proposed in this paper to overcome the problem of the performance issue which exists in the density based clustering algorithms. In this algorithm, number of RegionQuery call has been reduced as well as some RegionQuery calls speed has been improved. For reducing the RegionQuery
function calls, FDBSCAN Algorithm’s [3] selected representative objects as seed objects approach during the cluster expansion has been used in this solution and this approach has been proved theoretically using the following Lemmas 1 and 2. As the RegionQuery retrieve the neighbour objects which belong inside the Eps radius, Circle lemmas are given and which can be directly used in the RegionQuery optimization.
Lemma 1: Minimum number of identical circles required to cover the circumference of a circle with same radius which passes through the centres of other circles is three.
Proof: Let C and C1 be the identical circles of radius r with centre at O and O1 respectively. Assume the circle C passes through the centre O1 of the circle C1 and the circle C1 passes through the centre O of the circle C . Let the circles intersect at P and Q .

Figure 1 Two Identical Circles’ Intersection with respect to first circle’s Center Point.
Clearly, OP=OQ=r;O1P=O1Q=r and OO1=r.
ΔO1OP and ΔO1QO are equilateral.
∠POO1=∠QOO1=60∘∴∠POQ=∠POO1+∠QOO1=120∘
Now length of arc PO1Q=360∘120∘×2πr=32πr
32πr.
Thus arcual length 3 of the circumference of the given circle C is covered by C1. In order to cover the remaining part of the circumference of circle C , draw a circle C2 of same radius r with centre O2, passes through O and P . Let C2 intersect C at another point R (say).

Figure 2 Four Identical Circles intersection w.r.t first Circle’s center point.
Length of arc PO2R=32πr32πr [proceeding as above]
i.e., arcual length 3 of the circumference of the given circle C is covered by C2
34πr
Thus the circles C1 and C2 can able to cover only 3 part of the circumference of the circle C. i.e., in order to cover the complete circumference of the circle C we are required to draw one more circle C3 passes through O,Q and R with centre at O3 and radius r.
32πr
Length of arc RO3Q=32πr
of arcRO3Q=3×32πr=2πr, which is the perimeter of the circumference of the circle C. Hence minimum three identical circles required to cover the circumference of a circle with same radius which passes through the centres of other circles.
Lemma 1 proves that the minimum requirement to cover the circumference of the center circle and these minimum circles selection is equivalent to the RegionQuery call in the DBSCAN algorithm. In the real scenario, three RegionQuery call is not sufficient to cover most the neighbours which exist in the center object’s neighbours when the objects in the dataset is distributed uniformly(assume the objects are distributed uniformly and the distance between an object and its neighbour is 1). Moreover these three RegionQuery function calls are not sufficient to cover immediate neighbours of the center object’s neighbours and this problem is explained below:

Figure 3 Missing immediate neighbour Objects.
Above picture shows that a circle (“Original Circle”) is been intersected by three other identical circles. Even though the three circles are covering the full circumference of the original circle, these three circles are not able to cover center circle’s immediate neighbours which are marked in red colour (p1, p2 and p3). i.e. even if the distance between the intersection point and the immediate neighbour point is 1 , above scenario can’t cover the all its immediate neighbours. So the Lemma 2 has been introduced to prove the minimum circles requirement to cover all the immediate neighbours.
Lemma 2: Four identical circles are sufficient to cover all the immediate neighbour objects of the original circle when the objects are distributed uniformly.

Figure 4 Minimum Circles to cover the immediate neighbours.
Clearly, O3OO2P is a square of side r .
∴OP= Diagonal of the square of side r=r2
Distance AP=r2−r=2−1r=0.4142r
Thus four circles are able to cover the objects which are at most 0.4142 r distance apart from the circumference of the original circle C.
So we need minimum four RegionQuery call to cover all the immediate neighbours of the center Object’s neighbours and this will cover >80% of the neighbour objects of center object’s neighbours. This can be proved as follows:
Lemma 3: Four Identical Circles are sufficient to cover more than 80% of the neighbour objects of center circle when objects are distributed uniformly.

Figure 5 Neighbours unreachable area.
Area of outer circle (with radius 2r ) =πrrT=4πr2
Area of the square PQRS (with side 2r ) =rrT=4r2
Total area of four semi circles (each with radius r) =4×2πr2=2πr2
Hence area of unmarked region
=4r2+
2πr2
∴ Area of marked region =4πr2−(4r2+2πr2)=2πr2−4r2=2(π−2)r2
Percentage of area in outer circle covered by the marked area = 4πr22(π−2)r2×100%
=(ππ−2)×50%
Hence the area occupied by the marked region is <20 percentage.
So in the real time scenario we can conclude that if we select four seed objects for the cluster expansion from the center object’s neighbours we have the chances to ignore ∼20% of the objects which present in the border region and the previous FDBSCAN algorithm ignore these objects. In this solution, this problem has been rectified and all the border objects have been considered for the clustering operation.
To improve the performance of the algorithm, MEDBSCAN Algorithm [6] approach has been applied. So there are two types of Regionquery functions have been introduced in this algorithm namely, LongRegionQuery and ShortRegionQuery. First LongRegionQuery function will be called to get the region objects present in Eps neighbours as well as 2∗ Eps neighbours surrounded by the given object, the Eps distance neighbours from the center object will be stored in the InnerRegionObjects queue and the objects which are greater than Eps and less than or equal to 2∗ Eps distance from the center objects will be stored in OuterRegionObjects queue respectively. Later the selected seed objects present in the Eps neighbour region will be processed using the ShortRegionQuery function call. So the ShortRegionQuery function call will be always faster than the LongRegionQuery function as it needs to process only few objects which are present in the InnerRegionObjects as well as OuterRegionObjects and no need to process the entire objects present in the data set.
Another change in the proposed solution to improve the speed is modification of queue structure. i.e InnerRegionObjects and OuterRegionObjects queues are the combination of four sub queues.
RegionObjectsQueue
{
TopRightQueue;
RightBottomQueue;
BottomLeftQueue;
LeftTopQueue;
}
So InnerRegionObjects and OuterRegionObjects queues will maintain the corresponding region objects internally in four queues. Following diagram shows each queue’s object storage areas.

Figure 6 RegionObjectsQueue’s storage area classification.
This type of separation helps to minimize the unwanted distance computation while processing the border objects. i.e. while processing OuterRegionObjects queue’s unprocessed objects, we can consider only the adjacent portion of the InnerRegionObjects queue’s objects and other non adjacent portions objects can be ignored. This concept has been explained as follows.
Let ’ O ’ is an Outer Circle with radius 2r and ’ I ’ is an inner circle with radius r. Both of these circles are sharing the same Center point ’ C ’ and these two circles are equally divided into four parts as shown in the below picture (to perform the RegionQuery operation).
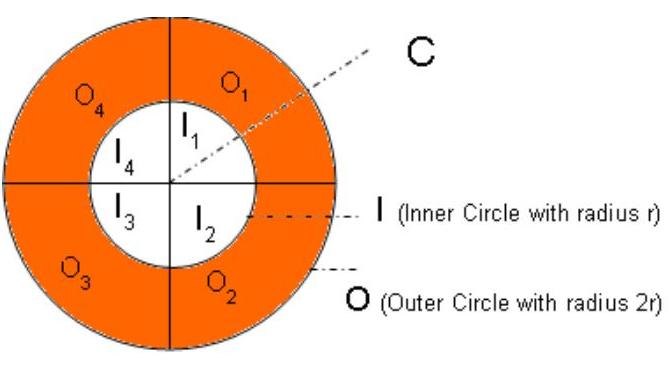
Figure 7 Inner and Outer Region Objects.
Here the inner circle objects’ neighbour objects are present in the outer circle’s marked area (with brown colour) and the inner circle itself. Now we can confirm that any object present in the inner circle’s any one of the quarter area ( 11 OR 12 OR 13 OR 14 ), will have its neighbour(s) in the 3 of the adjacent quarter part of the outer circle and the inner circle itself (four quarter parts). Thus we can ignore the outer circle’s non adjacent quarter part from the unnecessary computation.
(e.g)

Figure 8 Availability of Neighbour Objects in the Circle’s Portion.
In the above diagram Inner Circle’s I3 quarter portion has been considered for the neighbour computation. The object present in the I3 quarter portion will have its neighbours in O4,O5,O2 and the Inner circle itself ( I1,I2,I3 and I4 ), but not in O1 portion. i.e. Maximum r distance is the valid distance for neighbour computation and I3 's object require minimum r+1 distance to reach another object which is present in the O1 portion and this condition is not possible (Invalid condition has been shown in the diagram in red colour). Similarly while processing the border objects present in the OuterRegion, only the adjacent quarter portion of inner region objects are enough for the computation to know whether it is density reachable to any of the objects present in the InnerRegionObjects.
This is another optimization done in the new algorithm to speed up the computation as well as improve the accuracy of output. In the FDBSCAN algorithm, chances of missing the core objects as well as border objects are applicable and in this new approach all the border objects have been covered. Also it is proved that the core objects loss is very rare case and the new solution is better in most of the cases in the real time scenario.
InnterRegionObjects’ TopRight, RightBottom, BottomLeft and LeftTop Queues each for the further cluster expansion and push the selected objects to FourObjectsQueue. The selected objects should have the max distance from the center object o.
8. Assign ClusterID to all the UNCLASSIFIED and NOISE type Objects present in the InnerRegionObjects.
9. For each object T∈ FourObjectsQueue
10. Call ShortRegionQuery function with InnerRegionObjects, OuterRegionObjects, Eps and Object T to obtain the ShortRegionObjects.
11. Select four UNCLASSIFIED objects from the ShortRegionObjects’ TopRight, RightBottom,
BottomLeft and LeftTop Queues for the further cluster expansion. The selected Objects should have the max distance from the center object T. Push the selected objects to SeedQueue for the further processing.
12. Assign ClusterID to all the UNCLASSIFIED and NOISE type Objects present in the ShortRegionObjects.
13. End For
14. Remove the clustered objects from the OuterRegionObjects and process the remaining (UNCLASSIFIED and NOISE type) Objects to know if any one of the InnerRegionObjects neighbour present in the UNCLASSIFIED and NOISE type OuterRegionObjects. i.e if any remaining objects present in the OuterRegionObjects is density reachable from the center object o’s neighbour, assign ClusterID to the Object.
15. Pop the objects s from SeedQueue, Repeat the steps from 4-14 and until the SeedQueue is Empty. For all the above steps replace the object o with SeedQueue Object s wherever it is applicable.
16. Else
17. Mark o as NOISE
18. End If
19. End For
This algorithm read the same input as like original DBSCAN and all the objects are initialized as UNCLASSIFIED in the beginning. Afterwards all the UNCLASSIFIED objects are processed one by one. So the algorithm starts with LongRegionQuery function call to obtain the Neighbour objects (InnerRegionobjects and OuterRegionObjects) and the cluster expansion will happen only if the current object is a core object, otherwise the current object will be market as NOISE. During the cluster expansion, the new Cluster ID will get created and four UNCLASSIFIED objects are selected from the InnerRegionobjects’ four queues each and these objects should have the maximum distance from the center object. After assigning the Cluster ID to all the Objects present in the InnerRegionObjects queue, the selected four objects will be processed. Here the four objects are the maximum count and if there is no UNCLASSIFIED object present in one or more specific queues, the selected objects count will be less than 4. For processing these objects, ShortRegionQuery has been used and each ShorRegionQuery operation, maximum four seed objects will be selected which meets the above condition and pushed into seed queue for the further cluster expansion. The ShortRegionQuery takes the return array objects of LongRegionQuery function and will not process the whole Data set in the subsequent iteration. Thus the performance improvement has been guaranteed when the Eps value is reasonably insensitive. The Cluster ID will be assigned to the ShortRegionQuery’s output objects if the object is either UNCLASSIFIED or NOISE. Now the remaining UNCLASSIFIED or NOISE type objects present in the OuterRegionObjects queue is processed and which uses the “Neighbour computation Ignore Case” computation approach to minimize the computation and speed up the performance. After repeating these steps as mentioned in the algorithm and when the SeedQueue become empty, the current cluster expansion will stop and the control moves to process the next object UNCLASSIFIED type object using the parent for loop. The whole clustering process will be over once the main loop visits the entire N objects present in the data set.
The basic DBSCAN, Fast DBSCAN and proposed Optimized DBSCAM algorithms are implemented in Visual C++ (2008) on Windows Vista OS and tested using two dimensional Dataset. To know the real performance difference achieved in the new algorithm, we haven’t used any additional data structures (like spatial tree) to improve the performance. These algorithms are tested using two dimensional synthetic dataset and the performance results are shown below.
Table 1 Running time of Algorithms in Seconds
| DBSCAN | FDBSCAN | ODBSCAN | ||||
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
| 300 | 0.096 | 0 | 0.078 | 3 | 0.064 | 0 |
| 500 | 0.274 | 0 | 0.185 | 11 | 0.128 | 1 |
| 700 | 0.483 | 0 | 0.256 | 26 | 0.177 | 3 |
| 1200 | 1.024 | 0 | 0.581 | 34 | 0.345 | 7 |
| 2500 | 4.850 | 0 | 1.021 | 77 | 0.662 | 13 |
Above table shows that the new algorithm’s performance is better to the existing algorithms in terms of computation time and the new algorithm has small number of object loss than the Fast DBSCAN algorithm.
In this paper we have proposed ODBSCAN algorithm to improve the performance with less amount of object loss. In this new algorithm FDBSCAN and MEDBSCAN algorithms approach has been used to improve the performance. Also some new techniques have been introduced to minimize the distance computation during the RegionQuery function call. Eventually the performance analysis and the output shows that the newly proposed ODBSCAN algorithm gives better output, at the same time with good performance.
In this algorithm, all the border objects have been considered for the clustering process. But there are few possibilities to miss the core objects and which causes some loss of objects. Though the new algorithm gives better result than the previous FDBSCAN algorithm, this problem needs to be resolved in the further work to give the accurate result with same performance.
[1] Ester M., Kriegel H.-P., Sander J., and Xu X. (1996) “A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise” In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (KDD’96), Portland: Oregon, pp. 226-231
[2] J. Han and M. Kamber, Data Mining Concepts and Techniques. Morgan Kaufman, 2006.
[3] G. Karypis, E. H. Han, and V. Kumar, “CHAMELEON: A hierarchical clustering algorithm using dynamic modeling,” Computer, vol. 32, no. 8, pp. 68-75, 1999.
[4] M. Ankerst, M. Breunig, H. P. Kriegel, and J. Sander, “OPTICS: Ordering Objects to Identify the Clustering Structure, Proc. ACM SIGMOD,” in International Conference on Management of Data, 1999, pp. 49-60.
[5] A. Hinneburg and D. Keim, “An efficient approach to clustering in large multimedia data sets with noise,” in 4th International Conference on Knowledge Discovery and Data Mining, 1998, pp. 58-65.
[6] SHOU Shui-geng, ZHOU Ao-ying JIN Wen, FAN Ye and QIAN Wei-ning.(2000) “A Fast DBSCAN Algorithm” Journal of Software: 735-744.
[7] Li Jian; Yu Wei; Yan Bao-Ping; , “Memory effect in DBSCAN algorithm,” Computer Science & Education, 2009. ICCSE 199. 4th International Conference on , vol., no., pp.31-36, 25-28 July 2009.
J. Hencil Peter is Research Scholar, St. Xavier’s College (Autonomous), Palayamkottai, Tirunelveli, India. He earned his MCA (Master of Computer Applications) degree from Manonmaniam Sundaranar University, Tirunelveli. Now he is doing Ph.D in Computer Applications and Mathematics (Interdisciplinary) at Manonmaniam Sundranar University, Tirunelveli. His interested research area is algorithms inventions in data mining.
Dr. A. Antonysamy is Principal of St. Xavier’s College, Kathmandu, Nepal. He completed his Ph.D in Mathematics for the research on “An algorithmic study of some classes of intersection graphs”. He has guided and guiding many research students in Computer Science and Mathematics. He has published many research papers in national and international journals. He has organized Seminars and Conferences in state and national level.
Density based clustering techniques like DBSCAN can find arbitrary shaped clusters along with noisy outliers. A severe drawback of the method is its huge time requirement which makes it a unsuitable one for large data sets. One solution is to apply DBSCAN using only a few selected prototypes. But because of this the clustering result can deviate from that which uses the full data set. A novel method proposed in the paper is to use two types of prototypes, one at a coarser level meant to reduce the time requirement, and the other at a finer level meant to reduce the deviation of the result. Prototypes are derived using leaders clustering method. The proposed hybrid clustering method called l-DBSCAN is analyzed and experimentally compared with DBSCAN which shows that it could be a suitable one for large data sets.
2013
In Data minting, clustering plays a very important role. The process of grouping a set of physical or abstract objects into classes of similar objects is called clustering. Density Based Clustering is a well-known clustering algorithm which having advantages for finding out the clusters of different shapes and size from a large amount of data that contains noise and outliers. In this paper, I have presented a study of DBSCAN algorithm and its further enhancement based on the varied densities.
2017
Density based clustering is an emerging field of data mining now a days. There is a need to enhance Research based on clustering approach of data mining. There are number of approaches has been proposed by various author. VDBSCAN, FDBSCAN, DD_DBSCAN, and IDBSCAN are the popular methodology. These approaches are use to ignore the information regarding attributes of an objects. This paper is collection of various information of density based clustering. It also throws some light on the DBSCAN.
International Journal of Machine Learning and Computing, 2013
Clustering problem is an unsupervised learning problem. It is a procedure that partition data objects into matching clusters. The data objects in the same cluster are quite similar to each other and dissimilar in the other clusters. The traditional algorithms do not meet the latest multiple requirements simultaneously for objects. Density-based clustering algorithms find clusters based on density of data points in a region. DBSCAN algorithm is one of the density-based clustering algorithms. It can discover clusters with arbitrary shapes and only requires two input parameters.In this paper, we propose a new algorithm based on DBSCAN. We design a new method for automatic parameters generation that create clusters with different densities and generates arbitrary shaped clusters. The kd-tree is used for increasing the memory efficiency. The performance of proposed algorithm is compared with DBSCAN. Experimental results indicate the superiority of proposed algorithm.
Clustering is one of the data mining techniques that extracts knowledge from spatial datasets. DBSCAN algorithm was considered as well-founded algorithm as it discovers clusters in different shapes and handles noise effectively. There are several algorithms that improve DBSCAN as fast hybrid density algorithm (L-DBSCAN) and fast density-based clustering algorithm. In this paper, an enhanced algorithm is proposed that improves fast density-based clustering algorithm in the ability to discover clusters with different densities and clustering large datasets.
Emergence of modern techniques for scientific data collection has resulted in large scale accumulation of data pertaining to diverse fields. Cluster analysis is a primary method for database mining [8]. Among different types of cluster the density cluster has advantages as its clusters are easy to understand and it does not limit itself to shapes of clusters. But existing density-based algorithms are lagging behind. Almost all of the well-known clustering algorithms require input parameters which are hard to determine but have a significant influence on the clustering result. Furthermore, for many real-data sets there does not even exist a global parameter setting for which the result of the clustering algorithm describes the intrinsic clustering structure accurately [1][2]. This paper gives a survey of density based clustering algorithms. DBSCAN [15] is a base algorithm for density based clustering techniques. It can detect the clusters of different shapes and sizes from large amount of data which contains noise and outliers. The main drawback of traditional clustering algorithm was largely recovered by VDBSCAN algorithm. But in VDBSCAN algorithm the value of parameter ‘K’ was a user input dependent parameter. It largely degrades the efficiency of permanent Eps. In our proposed method the Eps is determined by the value of ‘k’ in varied density based spatial cluster analysis by declaring ‘k’ as variable one by using algorithmic average determination and distance measurement by Cartesian method and Cartesian product on two dimensional spatial dataset where data are sparsely distributed. So the objective is to enhance the existing DBSCAN algorithm by automatically selecting the input parameters and to find the density varied clusters. The proposed algorithm discovers arbitrary shaped clusters, requires no input parameters and uses the same definitions of DBSCAN algorithm.
Mining knowledge from large amounts of spatial data is known as spatial data mining. It becomes a highly demanding field because huge amounts of spatial data have been collected in various applications ranging from geo-spatial data to bio-medical knowledge. The amount of spatial data being collected is increasing exponentially. So, it far exceeded human's ability to analyze. Recently, clustering has been recognized as a primary data mining method for knowledge discovery in spatial database. The development of clustering algorithms has received a lot of attention in the last few years and new clustering algorithms are proposed. DBSCAN is a pioneer density based clustering algorithm. It can find out the clusters of different shapes and sizes from the large amount of data containing noise and outliers. This paper shows the results of analyzing the properties of density based clustering characteristics of three clustering algorithms namely DBSCAN, k-means and SOM using synthetic two dimensional spatial data sets.
The Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), 2014
Data Mining is all about data analysis techniques. It is useful for extracting hidden and interesting patterns from large datasets. Clustering techniques are important when it comes to extracting knowledge from large amount of spatial data collected from various applications including GIS, satellite images, X-ray crystallography, remote sensing and environmental assessment and planning etc. To extract useful pattern from these complex data sources several popular spatial data clustering techniques have been proposed. DBSCAN (Density Based Spatial Clustering of Applications with Noise) is a pioneer density based algorithm. It can discover clusters of any arbitrary shape and size in databases containing even noise and outliers. DBSCAN however are known to have a number of problems such as: (a) it requires user's input to specify parameter values for executing the algorithm; (b) it is prone to dilemma in deciding meaningful clusters from datasets with varying densities; (c) and it incurs certain computational complexity. Many researchers attempted to enhance the basic DBSCAN algorithm, in order to overcome these drawbacks, such as VDBSCAN, FDBSCAN, DD_DBSCAN, and IDBSCAN. In this study, we survey over different variations of DBSCAN algorithms that were proposed so far. These variations are critically evaluated and their limitations are also listed.
As a research branch of data mining, clustering, as an unsupervised learning scheme, focuses on assigning objects in the dataset into several groups, called clusters, without any prior knowledge. Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is one of the most widely used clustering algorithms for spatial datasets, which can detect any shapes of clusters and can automatically identify noise points. However, there are several troublesome limitations of DBSCAN: (1) the performance of the algorithm depends on two specified parameters, ε and MinPts in which ε represents the maximum radius of a neighborhood from the observing point and MinPts means the minimum number of data points contained in such a neighborhood. (2) The time consumption for searching the nearest neighbors of each object is intolerable in the cluster expansion. (3) Selecting different starting points results in quite different consequences. (4) DBSCAN is unable to identify adjacent clusters of various densities. In addition to these restrictions about DBSCAN mentioned above, the identification of border points is often ignored. In our paper, we successfully solve the above problems. Firstly, we improve the traditional locality sensitive hashing method to implement fast query of nearest neighbors. Secondly, several definitions are redefined on the basis of the influence space of each object, which takes the nearest neighbors and the reverse nearest neighbors into account. The influence space is proved to be sensitive to local density changes to successfully reduce the amount of parameters and identify adjacent clusters of different densities. Moreover, this new relationship based on the influence space makes the insensitivity to the ordering of inputting points possible. Finally, a new concept—core density reachable based on the influence space is put forward which aims to distinguish between border objects and noisy objects. Several experiments are performed which demonstrate that the performance of our proposed algorithm is better than the traditional DBSCAN algorithm and the improved algorithm IS-DBSCAN.
Density based clustering techniques like DBSCAN can find arbitrary shaped clusters along with noisy outliers. A severe drawback of the method is its huge time requirement which makes it a unsuitable one for large data sets. One solution is to apply DBSCAN using only a few selected prototypes. But because of this the clustering result can deviate from that which uses the full data set. A novel method proposed in the paper is to use two types of prototypes, one at a coarser level meant to reduce the time requirement, and the other at a finer level meant to reduce the deviation of the result. Prototypes are derived using leaders clustering method. The proposed hybrid clustering method called l-DBSCAN is analyzed and experimentally compared with DBSCAN which shows that it could be a suitable one for large data sets.
Journal of Physics: Conference Series, 2019
Bioinformatics alludes to the accumulation, grouping, storage and the investigation of biochemical and organic information. It uses PCs particularly, as executed toward sub-atomic hereditary qualities and genomics. Data mining is utilized to extract the data from a lot of information. Data mining comprise of two models, they are predictive and descriptive. Managing data intends to assemble data into an arrangement of classes either with the end goal to learn new antiquities or see new domains. For this reason specialists have dependably searched for the shrouded examples in information that can be characterized and contrasted and other known thoughts dependent on the comparability or disparity of their credits as indicated by all around characterized rules. We have shown the overview of different information digging algorithms for the combination of different examination instruments material specifically explore errands. There is no particular clustering algorithm, however different algorithm are used dependent on domain of information that establishes a group and the level of proficiency required. Clustering techniques are classified dependent on various methodologies. This paper is a review of few clustering methods out of numerous in data mining. The Clustering techniques which have been reviewed are: K-medoids, Fuzzy Cmeans, K-means, Density-Based Spatial Clustering of Applications with Noise and Self-Organizing Map grouping. This paper overviewed the some algorithm gives the best outcome. The scientists utilized diverse arrangement algorithm in which are to be specific K-Nearest Neighbor classifiers, Artificial Neural Networks, Bayesian system, Decision tree, Support Vector Machine.
Journal of Geospatial Information Technology
Identifying stopping points of trajectories is a preliminary and necessary step in the study of moving objects and has a major impact on spatial plans and services. In this study we use trajectory clustering to extract stopping points. DBSCAN algorithm (spatial clustering based on density of applications with noise) is the basic algorithm of density-based clustering methods, which despite its advantages has some shortcommings such as difficulty in determining input parameters, inability to detect clusters with different densities and not paying attention to round trip problem. In the proposed method, which is based on density, we use of spatial and temporal indices and several neighborhood radii to extract stop points. Solving the round trip problem, extracting clusters with different densities and reducing the degree of dependence of the results on input parameters are the advantages of the proposed method.In order to evaluate the proposed method, this method was implemented on the data obtained by handheld GPS in Arak city and the data related to the Geolife research project. The obtained results were compared with the results of five other algorithms including DBSCAN, ST-BDSCAN, VDBSCAN, DVBSCAN and K-means. Compared to the manual GPS route data in Arak city, the stop locations extracted by the proposed algorithm and the mentioned algorithms are 100%, 25%, 75%, 50%, 75% and 50%, respectively, which are correctly extracted and show the superiority of the developed method. Also, after extracting the stopping and moving points, indicators from Geolife data were determined to identify working and non-working days (holidays) with which the proposed method was able to act successfully up to 94.06%.The results show a decrease in the dependence of the results on input parameters, the accurate extraction of stopping points, a reduction in the standard deviation within the clusters, and an increase in the distance between the centers of the clusters.