 Iain Richardson
Iain Richardson580 California St., Suite 400
San Francisco, CA, 94104
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser.
2017, IASA journal No 47
Since the first commercially viable video codec formats appeared in the early 1990s, we have seen the emergence of a plethora of compressed digital video formats, from MPEG-1 and MPEG-2 to recent codecs such as HEVC and VP9. Each new format offers certain advantages over its predecessors. However, the increasing variety of codec formats poses many questions for anyone involved in collecting, archiving and delivering digital video content, such as: ■ Which codec format (if any) is best? ■ What is a suitable acquisition protocol for digital video? ■ Is it possible to ensure that early ‘born digital’ material will still be playable in future decades? ■ What are the advantages and disadvantages of converting (transcoding) older formats into newer standards? ■ What is the best way to deliver video content to end-users? In this article I explain how a video compression codec works and consider some of the practical concerns relating to choosing and controlling a codec. I discuss the motivations behind the continued development of new codec standards and suggest practical measures to help deal with the questions listed above.
AI
The research indicates that newer codecs such as HEVC require up to 50% more computational power than older standards like H.264 to achieve higher compression ratios without significant quality loss.
Cisco reported that by 2020, video data accounted for over 80% of all consumer internet traffic, largely driven by the advent of high-resolution content.
A higher quantization parameter (QP) can result in compression ratios exceeding 100:1, but typically sacrifices visual quality, whereas lower QP settings maintain quality at the cost of larger file sizes.
Transcoding can introduce generation loss with each lossy encoding step, leading to progressive degradation of visual quality if not managed properly, especially in repeated compression scenarios.
As higher resolution formats like UHD become standard, the storage requirements can increase significantly, necessitating advanced compression techniques to manage bandwidth and storage without sacrificing playback quality.








High processing speed is required to support computation intensive applications. Cache memory is used to improve processing speed by reducing the speed gap between the fast processing core and slow main memory. However, the problem of adopting cache into computing systems is twofold: cache is power hungry (that challenges energy constraints) and cache introduces execution time unpredictability (that challenges supporting real-time multimedia applications). Recently published articles suggest that using cache locking improves predictability. However, increased cache activities due to aggressive cache locking make the system consume more energy and become less efficient. In this paper, we investigate the impact of cache parameters and cache locking on power consumption and performance for real-time multimedia applications running on low-power devices. In this work, we consider Intel Pentium-like single-processor and Xeon-like multicore architectures, both with two-level cache memory hierarchy, using three popular multimedia applications: MPEG-4 (the global video coding standard), H.264/AVC (the network friendly video coding standard), and recently introduced H.265/HEVC (for improved video quality and data compression ratio). Experimental results show that cache locking mechanism added to an optimized cache memory structure is very promising to increase the performance/power ratio of low-power systems running multimedia applications. According to the simulation results, performance can be improved by decreasing cache miss rate down to 36 % and the total power consumption can be saved up to 33 %. It is also observed that H.265/HEVC has significant performance advantage over H.264/AVC (and MPEG-4) for smaller caches.
Digital video compression technologies have become part of life, in the way visual information is created, communicated and consumed. Some application areas of video compression focused on the problem of optimizing storage space and transmission bandwidth (BW). The two dimensional discrete cosine transform (2-D DCT) is an integral part of video and image compression, which is used in Moving Picture Expert Group (MPEG) encoding standards. Thus, several video compression algorithms had been developed to reduce the data quantity and provide the acceptable quality standard. In the proposed study, the Matlab Simulink Model (MSM) has been used for video coding/compression. The approach is more modern and reduces error resilience image distortion.
Journal of Real-Time Image Processing, 2015
The popularity of the new standard H.265 (High Efficiency Video Coding) depends on two factors: the rapidity of deploying clients for the most outstanding platforms and the capacity of service providers to develop efficient encoders for serving demanding multimedia services such as Live TV. Both encoders and decoders should inter-operate efficiently with the streaming protocols to limit the risks of implementation incompatibilities.This paper presents a synergy framework between High Efficiency Video Coding (HEVC) and Dynamic Adaptive Streaming over HTTP (DASH) that increases the compression capabilities of the encoder and opens new parallel encoding points for accelerating the video content coding and formatting processes. The synergy takes advantage of inter-motion prediction in HEVC for delimiting the segments of DASH protocol, which increases the motion compensation in each segment. Moreover, the impact of encoding multiple DASH representations is limited due to the parallel encoding presented in this paper.
Digital video compression technologies have become part of life, in the way visual information is created, communicated and consumed. Some application areas of video compression focused on the problem of optimizing storage space and transmission bandwidth (BW). The two dimensional discrete cosine transform (2-D DCT) is an integral part of video and image compression, which is used in Moving Picture Expert Group (MPEG) encoding standards. Thus, several video compression algorithms had been developed to reduce the data quantity and provide the acceptable quality standard. In the proposed study, the Matlab Simulink Model (MSM) has been used for video coding/compression. The approach is more modern and reduces error resilience image distortion.
The main goal of evolving image/video coding standardization is to achieve low bit rate, high image quality with reasonable computational cost for efficient data storage and transmission with acceptable distortion during video compression. The current scheme improves the generic decimation-quantization compression scheme by rescaling the data at the decoder side by introducing low complexity single-image Super Resolution(SR) techniques and by jointly exploring the down sampling/up sampling processes. The proposed approach uses a block compensation engine introduced by using Motion Matching based Sampling, quantization and scaling in order to reduce data processing/scanning time of computational units and maintains a low bit rate.This method scans the motion similarity between spatial and temporal regions for efficient video codec design and performs 2D correlation analysis in the video blocks and frames. This video compression scheme significantly improves compression performance along with 50% reduction in bitrate for equal perceptual video quality. Our proposed approach maintains a low bitrate along with reduced complexity and can achieve a high compression ratio.
In order to ensure compatibility among video codecs from different manufacturers and applications and to simplify the development of new applications, intensive efforts have been undertaken in recent years to define digital video standards Over the past decades, digital video compression technologies have become an integral part of the way we create, communicate and consume visual information. Digital video communication can be found today in many application sceneries such as broadcast services over satellite and terrestrial channels, digital video storage, wires and wireless conversational services and etc. The data quantity is very large for the digital video and the memory of the storage devices and the bandwidth of the transmission channel are not infinite, so it is not practical for us to store the full digital video without processing. For instance, we have a 720 x 480 pixels per frame,30 frames per second, total 90 minutes full color video, then the full data quantity of this video is about 167.96 G bytes. Thus, several video compression standards, techniques and algorithms had been developed to reduce the data quantity and provide the acceptable quality as possible as can. Thus they often represent an optimal compromise between performance and complexity. This paper describes the main features of video compression standards, discusses the emerging standards and presents some of its main characteristics.
IEEE Transactions on Image Processing, 2000
We propose a new coding technology for 3D video represented by multiple views and the respective depth maps. The proposed technology is demonstrated as an extension of the recently developed High Efficiency Video Coding (HEVC). One base view is compressed into a standard bitstream (like in HEVC). The remaining views and the depth maps are compressed using new coding tools that mostly rely on view synthesis. In the decoder, those views and the depth maps are derived via synthesis in the 3D space from the decoded base view and from data corresponding to small disoccluded regions. The shapes and locations of those disoccluded regions can be derived by the decoder without any side information transmitted. In order to achieve high compression efficiency, we propose several new tools like Depth-Based Motion Prediction, Joint High Frequency Layer Coding, Consistent Depth Representation and Nonlinear Depth Representation. The experiments show high compression efficiency of the proposed technology. The bitrate needed for transmission of even two side views with depth maps is mostly below 50% of the bitrate for a single-view video. Index Terms-3D video, coding, compression, MVD representation, HEVC, depth maps. Krzysztof Wegner received the M.Sc. degree from Poznań University of Technology in 2008. Currently he is working towards his Ph.D. there. He is co-author of several papers on free view television, depth estimation and view synthesis. His professional interests include video compression in multipoint view systems, depth estimation form stereoscopic images, view synthesis for free view television, face detection and recognition. He is involved in ISO standardization activities where he contributes to the development of the future 3D video coding standards. Jacek Konieczny received the M.Sc. and Ph.D. degrees from Poznań University of Technology, Poznań, Poland, in 2008 and 2013, respectively. He has been involved in several projects focused on multiview and 3D video coding. His research interests include representation and coding of multiview video scenes, free-viewpoint video, and 2-D and 3-D video-based rendering. He is involved in ISO standardization activities where he contributes to the development of the 3D video coding standard. Maciej Kurc received his M.Sc. (2008) from the Faculty of Electronics and Telecommunications, Poznań University of Technology, PL, where he currently is a Ph.D. student. His main areas of research are video compression and FPGA logic design. Jakub Siast received the M.Sc. degree (2009) from the Faculty of Electronics and Telecommunications, Poznań University of Technology, PL, where he is Ph.D. student. His current research interests include image processing and coding, developing of video coding algorithms, FPGA and microprocessor architecture design. Jakub Stankowski received the M.Sc. degree (2009) from the Faculty of Electronics and Telecommunications, Poznań University of Technology, PL, where he is a Ph.D. student. His current research interests include video compression, performance optimized video processing algorithms, software optimization techniques. Robert Ratajczak received the M.Sc. degree from the Faculty of Electronics and Telecommunications, Poznań University of Technology, PL, in 2010, where he is currently a Ph.D. student. His current research interests include stereoscopic images processing and coding, 3D surface reconstruction, object classification and detection. Tomasz Grajek received his M.Sc. and Ph.D. degrees from Poznań University of Technology in 2004 and 2010 respectively. At present he is an assistant at the Chair of Multimedia Telecommunications and Microelectronics.
Iain E. Richardson,Vcodex Ltd., UK
Not another video codec!
Since the first commercially viable video codec formats appeared in the early 1990s, we have seen the emergence of a plethora of compressed digital video formats, from MPEG-I and MPEG-2 to recent codecs such as HEVC and VP9. Each new format offers certain advantages over its predecessors. However, the increasing variety of codec formats poses many questions for anyone involved in collecting, archiving and delivering digital video content, such as:
In this article I explain how a video compression codec works and consider some of the practical concerns relating to choosing and controlling a codec. I discuss the motivations behind the continued development of new codec standards and suggest practical measures to help deal with the questions listed above.
‘Codec’ is a contraction of ‘encoder and decoder’. A video encoder converts ‘raw’ or uncompressed digital video data into a compressed form which is suitable for storage or transmission. A video decoder extracts digital video data from a compressed file, converting it into a displayable, uncompressed form. It is worth noting that:
Figure I compares the resolution of popular video formats:
| Format | Pixels per frame |
|---|---|
| Standard Definition (SD) | 720×576 (PAL) or 720×486 (NTSC) |
| 720p High Definition (HD) | 1440×720 |
| 1080p High Definition (Full HD) | 1920×1080 |
| Ultra HD* | 3840×2160 |
Making certain assumptions about colour depth’, one second of SD video recorded at 25 frames per second, requires 15.5 Mbytes of storage space. One second of Full HD video at 50 frames per second requires around 176 Mbytes of storage. This means that storing an hour-long Full HD video would require over 630 Gbytes of storage space. A key benefit of compression is that a compressed version of the same I-hour file might require only a few Gbytes of space. The exact amount of space required depends on a number of factors including the content of the video and the chosen playback quality, as we shall see later. Compression of video can:
Audio-visual material is increasingly captured in a compressed form. Unless your content is created using professional cameras and production tools, it is likely to be compressed during the recording process. For example, if you record video on a consumer device such as a digital camera, camcorder or smartphone, video is captured via the device’s camera, encoded and stored on the device’s internal storage in a compressed form. ‘Born digital’ audio-visual material is very often ‘born compressed’.
I 4:2:0 sampling and 8 bits per sample, with PAL format for the SD example. ↩︎

Figure I Video resolutions
A video codec can compress video material by exploiting two main factors:
Most of the video material that we watch has certain predictable characteristics that can be used to help compress the video. Pixels or regions that are close to each other in space or time are likely to be correlated, i.e. similar. Within a single video frame, spatially neighbouring pixels are often the same or similar, particularly when they are all part of the same image feature or region. We can often find the same or very similar pixels in a video frame before or after the current frame, either (a) in the same place, if there is no movement from frame to frame, or (b) in a nearby location, if there is movement of the camera or the objects in the frame. A video encoder exploits these spatial and temporal similarities in several ways to compress video. For example, during prediction, each block of pixels in a frame is predicted from nearby pixels in the same frame or from pixels in another, previously processed frame.
When we look at a visual scene, we only take in or attend to a relatively small amount of information (Anderson, Charles, et al., 2005). Many factors are at work, including the sensitivity of the human visual system to detail and movement, our attention to and interest in what is actually in the scene and our innate response to unusual or unexpected details. A human observer is not capable of paying attention to every pixel in a high definition video display. A (lossy) video encoder exploits this by discarding much of the visual information in a scene, removing fine details and small variations that would typically not be noticed by the viewer.
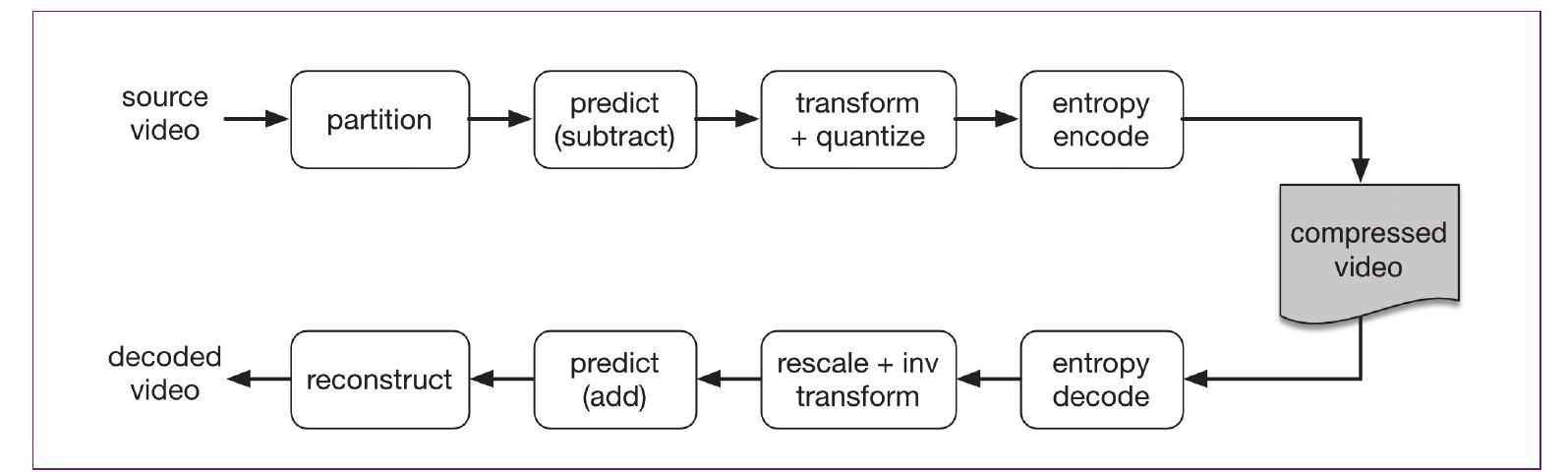
Most video compression encoders carry out the following steps to process and compress video, converting a series of video frames into a compressed bitstream or video file (Figure 3).
I. Partitioning: The encoder partitions the video sequence into units that are convenient for processing. A video clip is typically partitioned into -

Figure 2 Partitions
Many of the partitions within a frame are square or rectangular, with dimensions that are powers of two ( 16,32,64 etc). These dimensions are (a) easy for electronic devices to process efficiently using digital logic and processors and (b) easy to indicate or signal in the encoded file.
2. Prediction: Each basic unit or block is predicted from previously-coded data such as neighbouring pixels in the same frame (intra prediction) or pixels in previously coded frames (inter prediction). A prediction block is created that is as close a match as possible to the original block. The prediction is subtracted from the actual block to create a difference or residual block.
3. Transform and quantize: Each residual block is transformed into a spatial frequency domain using a two-dimensional transform such as a Discrete Cosine Transform (DCT) or a Discrete Wavelet Transform. Instead of storing each sample or pixel in the block, the block is converted into a set of coefficients which correspond to low, medium and high frequencies in the block. For a typical block, most of the medium and high frequency coefficients are small or insignificant. Quantization removes all of the insignificant, small-valued coefficients in each block. The quantization parameter (QP) controls the amount of quantization, i.e. how much data is discarded.
4. Entropy encoding: The video sequence is now represented by a collection of values including quantized coefficients, prediction information, partitioning information and ‘side’ or header information. All of these values and parameters are entropy encoded, i.e. they are converted into a compressed binary bitstream. An entropy encoder such as a Huffman or Arithmetic encoder represents frequently-occurring values and parameters with very short binary codes and less-frequent values and parameters with longer codes.
The output of all these steps is a compressed bitstream - a series of binary digits (bits) that takes up much less space than the original video frames and is suitable for transmission or storage.

Figure 3 Encoding and decoding steps
Most video encoders in current use carry out the steps described above. However, there is considerable variation within each of the steps, depending on the codec standard and on the particular software or hardware implementation.
A video decoder reverses the steps carried out by the encoder, converting a compressed bitstream into a displayable series of video frames. To decode a bitstream created as described in section 2.4 above, the decoder carries out the following steps:
I. Entropy decoding: The decoder processes the compressed bitstream and extracts all the values and parameters required to re-create the video clip.
A codec standard makes it possible for encoders and decoders to communicate with each other successfully. Conisider the example of a video that is recorded on a smartphone, encoded (compressed) and emailed to a PC where it is decoded and played back. The smartphone and the PC may be designed and manufactured by different companies. If the encoder and decoder conform to the same codec standard, we can ensure that the decoder will be able to successfully extract and play back the video clip, regardless of how the source and destination devices were designed.
A standard is a specification document created by a committee of technical experts. A video coding standard defines at least the following -
I. The format of a compressed video stream or file, i.e. exactly how each part of the coded file is represented.
2. A method of decoding the compressed file.
Typically, a video coding standard does not define an encoder (Figure 4). It is up to each manufacturer to decide how to design an encoder. The only requirement is that the bitstream produced by the encoder must be compliant with the standard, i.e. it has to conform to the format described by the standard and it must be decodeable by the method defined in the standard.

Figure 4 What a video coding standard covers
Since the first digital video coding standards were developed in the late 1980s/early 1990s, there have been a surprising number of standards released. Figure 5 shows some (but not all) of the key standards released over the last 25 years. Many were developed by working groups of the ISO/IEC and ITU-T international standards organisations. ISO/IEC standards include MPEG-2 (ISO/IEC 13818-2 and ITU-T Recommendation H.262, 1995), the standard used for the first digital TV services and for DVD Video. Some standards have been co-published by ISO/IEC and ITU-T, which is why H. 264 (ITU-T Recommendation H.264, 2003) (for example) is also known as MPEG-4 Part 10. The most recent publication of the ISO/IEC and ITU-T is H. 265 / HEVC, High Efficiency Video Coding, first released in 2013 (ITU-T Recommendation H.265, 2013).

Figure 5 Timeline of selected video coding standards
TheVP8 (IETF Request for Comments 6386, 2011) andVP9 formats were published by Google as part of the open source WebM initiative. At the time of writing (late 2016), new codec formats continue to be developed. The Joint Video Exploration Team (JVET) of ITU-T and ISO/ IEC is considering new technologies as part of its Future Video Coding (FVC) exploration. The Alliance for Open Media (AOM), a consortium of companies including Google, Cisco, Microsoft, Mozilla, Netflix and others, is developing the AVI codec format.
There are at least three factors behind the continued development and publication of new video codec formats and standards.
I. The demand for storing and transmitting increasingly high-resolution video content continues to rise. In the early days of broadcast and internet digital video, resolutions tended to be limited to Standard Definition or lower, and the volume of content was significantly lower.
2. This increase in high-resolution video content puts significant pressure on network and storage capacity, despite continuing increases in bandwidth. According to Cisco (Cisco Visual Networking Index, 2015), video data is increasingly dominating internet use and will make up over 80% of all consumer internet traffic by 2020.
3. Processing power continues to increase, so that it becomes feasible to carry out more complex processing of video, even on a mass-market device such as a smartphone.
Furthermore, new formats and usage scenarios are continuing to emerge. For example, 360 degree video involves an array of cameras that simultaneously capture video in all directions from a single central point. Playback on a conventional screen allows the viewer to move their viewpoint around to any angle, from within the scene. Free Viewpoint Video gives the viewer the freedom to observe a scene from the outside, selecting to view the scene from angle or
viewpoint. These new modes may have particular advantages for capturing events where a single, conventional viewpoint only records a small part of what is happening. These and other scenarios such as stereoscopic video, animation and screen sharing, may require new or modified standards.
Putting these factors together, there is a continued demand for better compression of video to support the increase in created, stored and transmitted video. Increasing processing power on consumer devices makes it possible to use new, more sophisticated video coding standards to meet this demand.
As new standards are released, manufacturers build support for new formats into devices such as tablets and smartphones. Typically, older standards such as MPEG-2 and H. 264 continue to be supported, so that a newly-manufactured device may be capable of decoding video in multiple formats including MPEG-2, H.264, HEVC andVP9. In a similar way, software players such as VLC and web browsers increasingly support a range of codec standards.
Coding video involves a trade-off between many different factors, including:
The fidelity of a video image depends on factors such as spatial resolution, frame rate and colour depth. Higher spatial resolutions such as 1080 p and UHD can give the appearance of a sharper, more detailed video image. However, there is some debate as to whether a human observer can actually tell the difference between 1080p and UHD video at longer viewing distances (Le Callet and Barkowsky, 2014). As humans, our sensitivity to fine detail is limited and at a certain viewing distance from a screen, it is no longer possible to observe the extra details added by a UHD display. Increased frame rates (e.g. 50 or 60 frames per second) can represent fast and complex motion with better fidelity. Higher colour depths, in which each colour component of a pixel is represented using 10 or more bits instead of the widely-used 8 bits per colour component, may give a more vivid impression of colours and ranges of brightness, depending on the capability of the display.
The quality of a decoded video image depends on how it was compressed. Lossless coding involves retaining all of the visual information present in the original video sequence. However, the amount of compression is likely to be limited to 2-3 times. Lossy coding offers the potential for much higher compression ratios, often 100 times or more, at a cost of a reduction in visual quality. So-called ‘visually lossless’ compression may be a suitable compromise for some archival scenarios, in which the compression ratio of a lossy codec is kept deliberately low, perhaps reducing the file size by a factor of 20 times or more, whilst maintaining visual quality at a level that is indistinguishable to a human observer.
Compression determines the size of the encoded video file and the bitrate (number of bits per second) required to stream or transmit the file. Many factors affect the amount of compression achieved by a particular codec for a particular video clip. The encoder quantization parameter (QP) is often used to control the amount of compression and the quality of the decoded video clip. A higher QP tends to produce more compression but also lower video quality. A lower QP gives less compression but maintains a higher video quality.
The amount of computation required to compress a video file determines how long it will take to process the file. In general, more compression can be achieved at the expense of increased computation. Encoding a video sequence involves many choices and repeated computation steps, such as finding the best prediction for each block of a video frame. Video compression software often has different options such as ‘fast’, ‘slow’ or ‘very slow’ encoding presets. This makes it possible to choose whether to encode slowly and achieve better compression, or to compress a file more quickly at the expense of a lower compression ratio. Newer standards such as HEVC or VP9 typically require more computation than older standards such as MPEG2 or H. 264 .
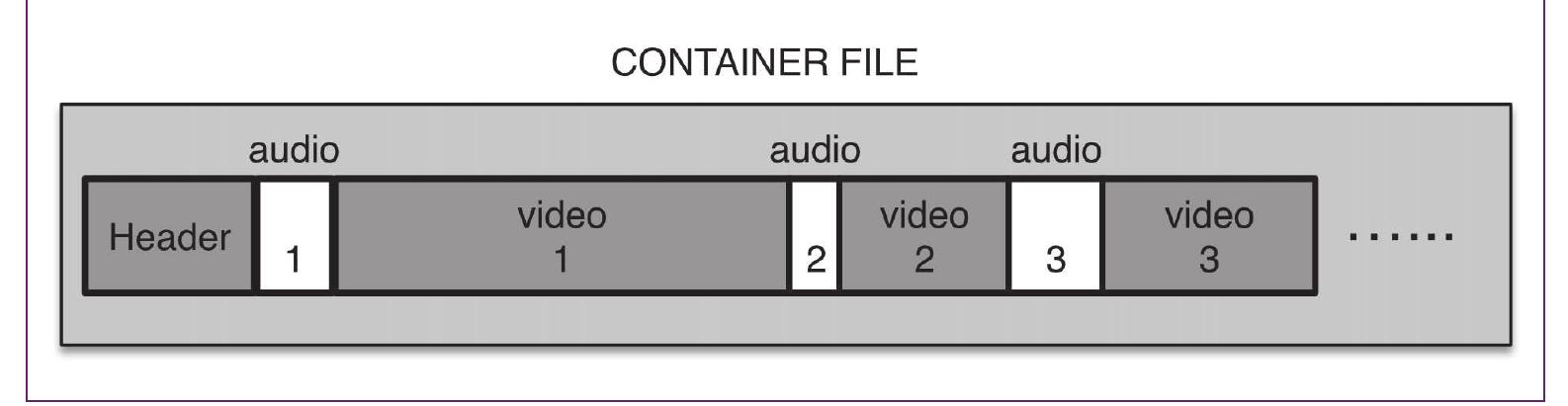
A coded video clip is typically stored in a container file, together with associated audio track(s) and side information such as metadata. Just as there are many video coding standards, there are a number of file format standards including:
In general, a container file will include:
The audio and video streams are often interleaved, i.e. chunks of coded video and associated audio are interspersed within the file (Figure 6).
There is considerable flexibility in the choice of container format, video format and audio format. For example, an MP4 file can contain video formats such as MPEG-2, MPEG-4, H. 264 or H. 265 and audio formats including MP3, AAC and others.

Figure 6 Container file
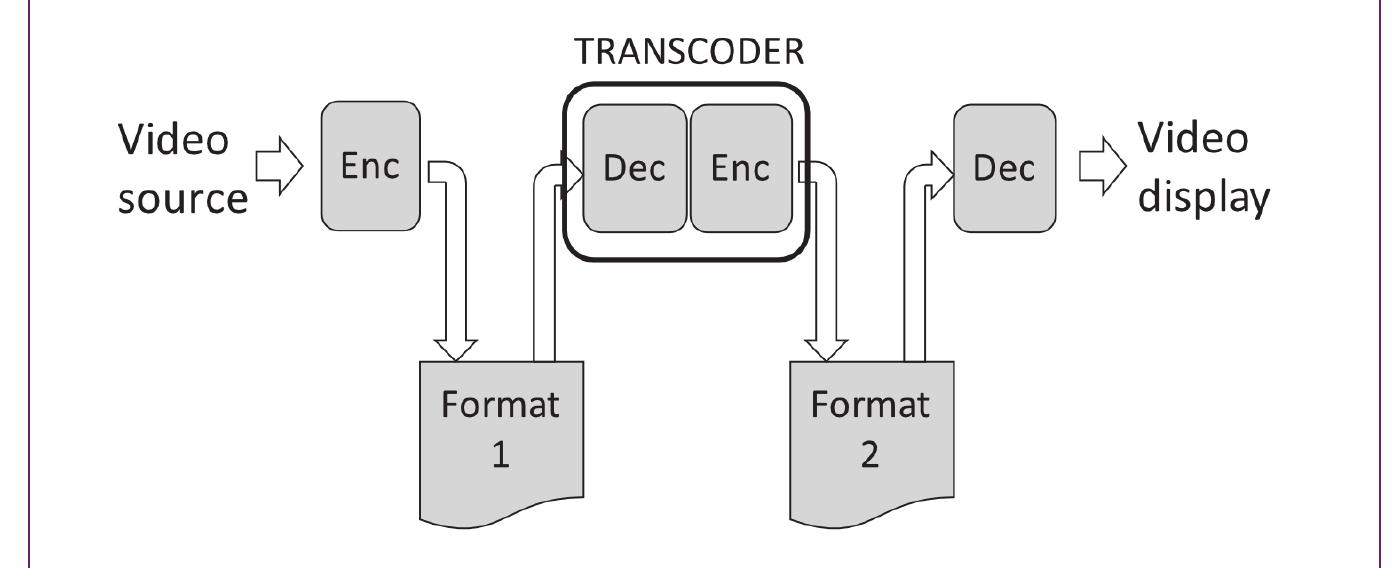
In a simple scenario (Figure 7), a video source is encoded into a compressed file (Format I) and decoded in order to play back the video. However, often it may be necessary to convert from one compressed format into another (Figure 8). Here, the compressed file (Format I) is converted into a new format, Format 2.Video and perhaps audio is decoded then re-encoded into the new format. This conversion process is known as transcoding. Transcoding may be necessary for a number of reasons, for example:
It is important to be aware that each transcoding step - more specifically, each encoding step - can introduce quality loss into the video and/or audio content. If the encoding step is lossy, then degradation is introduced every time the content is re-coded. This may lead to generation loss (Figure 9), such that the visual quality of the material progressively degrades with each conversion.

Figure 7 Single encode and decode

Figure 8 Transcoding

Figure 9 Generation loss
How much space is required to store an hour of compressed video? The answer depends on many factors, including:
With the correct choice of bitrate settings and/or quantization settings, it is generally possible to produce compressed files with either (a) a predictable file size or (b) a predictable visual quality, but not necessarily both at the same time.
Acquiring, encoding and perhaps transcoding video material is one side of the story. The other side is providing access to the video content once it is stored. It may be sufficient to simply provide the encoded file to the intended viewer, for example by copying the file onto portable media or delivering it via file transfer. However, if the stored file is maintained at a high fidelity and therefore has a large size, it may be necessary to derive a version that is more suitable for transfer or streaming.
Proxy versions :The archived file may be transcoded to a lower-resolution and/or lower-quality proxy version for delivery to an end user. Reducing resolution and/or quality will make the compressed file smaller and can be a simple way of controlling or limiting access to full resolution versions.
Streaming : Container formats such as MP4 can be constructed to be ‘streaming ready’, such that the audio and video samples are interleaved (Figure 6). The file is streamed by transferring it in a sequence of packets, each containing one or more chunks of audio and/or video data. The receiver stores incoming packets in a buffer and once enough data is available (say, a few seconds of video), playback can commence. The well-known phenomenon of buffering occurs when the stream of packets does not arrive quickly enough to maintain constant decoding and playback.
Adaptive streaming :The buffering problem can be mitigated or avoided by using an adaptive streaming protocol such as DASH (Dynamic Adaptive Streaming over HTTP) (ISO/IEC 23009I, 2014). A DASH server maintains multiple copies or representations of the video scene, each at a different bitrate (Figure 10). For example, the lowest-bitrate version might have a low spatial resolution (e.g. SD or lower) and may be encoded with a high QP so that the bitrate and the quality is low. Higher bitrate versions may have higher resolutions and/or lower QP settings. In a typical scenario, the receiver requests the lowest bitrate version first, so that playback can start quickly after a relatively small number of packets have been received. If packets are arriving quickly enough, the receiver requests a higher bitrate version and switches seamlessly to this version at certain switching points, e.g. every few seconds.
Example: The receiver of the stream shown in Figure 10 starts decoding and playback of the Medium Quality representation (Section I). The first section is received before playback is completed and so the receiver switches to the High Quality representation (Section 2). The channel bitrate drops significantly and so the receiver requests to switch to the Low Quality representation (Section 3). The viewer experiences continuous video delivery, albeit with a reduction in quality if the network rate drops.
DASH and other adaptive streaming technologies require multiple transcoded versions of the video clip to be created, with each section stored in a container file so that the required switchover points are available.

Figure 10 Adaptive streaming
Designing and specifying systems and protocols for archiving and retrieving coded video is a challenging task, as standards, electronic devices and user behaviours continue to change.Video resolution is increasing with each new generation of devices. For example, UHD resolution video recording is now supported by smartphones such as the iPhone 7 and Xperia ZS, and by an increasing range of consumer and professional cameras. As well as the challenges of higher resolutions and new codec formats, the way in which video is captured and disseminated continues to evolve.
Video footage of significant events is increasingly captured on a smartphone. With the rapid rise in user-generated video content, it is no longer possible to assume that content will be professionally captured in a well-lit environment. Content created on consumer devices such as smartphones and low-cost cameras is ‘born’ in an already compressed form.
Most video footage is still shot in the familiar format of a rectangular window. However, new ways of capturing video are beginning to emerge, such as 360 degree, stereoscopic and Free Viewpoint video, as discussed in Section 3.2. These and other departures from the traditional rectangular video scene offer particular challenges for coding, storing and delivering video.
Is it possible to future proof video archiving and delivery? The answer is probably not, since codec formats and usage patterns continue to evolve. However, the challenge of future proofing can be met at least partially by taking practical measures. During acquisition, it may be desirable specify an up-to-date codec that is likely to be supported for some time to come and a resolution such as 1080p that preserves visual information without taking up excessive storage space. Visually lossless rather than fully lossless compression may be an acceptable compromise between retaining important visual information and achieving reasonable compression. It is important to be aware that each transcoding or conversion process can introduce progressive degradation into audio-visual material. Finally, delivery or access to end users may be provided by deriving a reduced-quality, streamable version of stored content.
The rapid evolution of video capabilities, usage and formats in the last two decades implies that digital video technology will continue to change and develop for the foreseeable future. The only certainty is that further change is inevitable. However, by developing an understanding of the underlying principles and practical considerations of video compression coding, it is possible to specify and implement systems for the acquisition, storage and delivery of audio-visual media that can provide a good quality of service today and can adapt to the constantly changing landscape of digital video technology.
Anderson, Charles, David Van Essen, and Bruno Olshausen. (2005). ‘Directed visual attention and the dynamic control of information flow.’ In Neurobiology of Attention, Elsevier.
Cisco. (2015). Cisco Visual Networking Index: Forecast and Methodology, 2015-2020. http://www.cisco.com/c/dam/en/us/solutions/collateral/service-provider/visual-networking-index-vni/complete-white-paper-c11-481360.pdf (Date Accessed: 2016-12-28).
IETF Request for Comments 6386. (2011). ‘VP8 Data Format and Decoding Guide’.
ISO/IEC 13818-2 and ITU-T Recommendation H.262, (1995). ‘Generic coding of moving pictures and associated audio information:Video’, (MPEG-2 Video).
ISO/IEC 23009-I. (2014). ‘Dynamic Adaptive Streaming over HTTP - Part I’.
ITU-T Recommendation H.264. (2003). ‘Advanced video coding for generic audiovisual services’.
ITU-T Recommendation H.265. (2013). ‘High efficiency video coding’.
Le Callet, Patrick and Marcus Barkowsky. (2014). ‘On viewing distance and visual quality assessment in the age of Ultra High Definition TV’,VQEG eLetter,Video Quality Expert Group, 2014, Best Practices for Training Sessions, I (I), pp.25-30.
MSU Graphics and Media Lab. (2016). ‘HEVC/H. 265 Video Codecs Comparison’, August 2016. http://compression.ru/video/codec_comparison/hevc_2016/ (Date Accessed: 2016-12-28).
International Association of Sound and Audiovisual Archives Journal, 2018
‘Born digital’ often means ‘born compressed’ and it is increasingly likely that newly-created digital video material will have gone through at least some level of lossy compression. For this reason, it is important to understand the effect of video compression on visual quality. In this paper, I will introduce the concept of video compression and its relationship to video image quality. I will consider the factors that influence visual quality, including technical factors such as codecs and coding parameters, as well as the complex and only partly-understood factors that govern our perception of moving images. I will introduce methods of measuring and quantifying video quality and show how it is possible to compare the quality and performance of video processing systems, despite the limitations of quality measurement.
The arrival of auto stereoscopic displays demands for the efficient compression of video which can acquire forward compatibility. CT or MRI Medical imaging produces digital form of human body pictures. There exists a need for compression of these images for storage and communication purposes. Current compression schemes provide a very high compression rate with a considerable loss of quality. In medicine, it is necessary to have high image quality in region of interest, i.e. diagnostically important regions.The main goal of the efficient HEVC standardization effort is to enable significantly improved compression performance relative to existing standards-in the range of 50% bit-rate reduction for equal perceptual video excellence. This paper provides the technical features and characteristics of the HEVC standard.In addition,a forward compatible solution is proposed which uplifts the H.264/AVC based systems to HEVC based auto stereoscopic environment.
2007 IEEE 10th International Symposium on Workload Characterization, 2007
HD-VideoBench is a benchmark devoted to High Definition (HD) digital video processing. It includes a set of video encoders and decoders (Codecs) for the MPEG-2, MPEG-4 and H.264 video standards. The applications were carefully selected taken into account the quality and portability of the code, the representativeness of the video application domain, the availability of high performance optimizations and the distribution under a free license. Additionally, HD-VideoBench defines a set of input sequences and configuration parameters of the video Codecs which are appropriate for the HD video domain.