Measuring the impact of data center failures on a cloud-based emergency medical call systemConcurrency and Computation: Practice and Experience, 2019
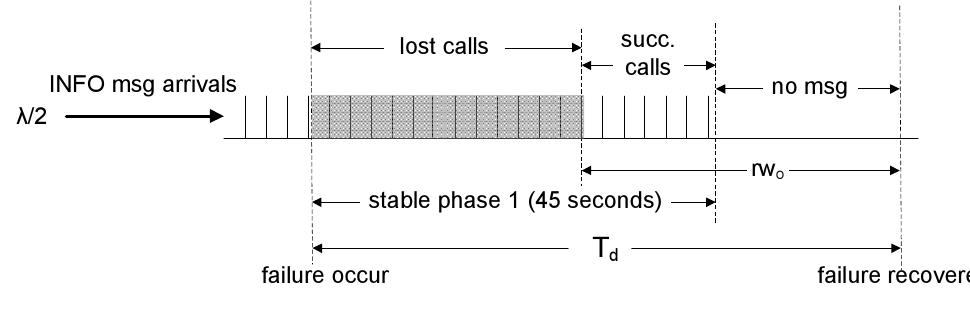
Emergency call services are expected to be highly available in order to minimize the loss of urgent calls and, as a consequence, minimize loss of life due to lack of timely medical response. This service availability depends heavily on the cloud data center on which it is hosted. However, availability information alone cannot provide sufficient understanding of how failures impact the service and users' perception. In this paper, we evaluate the impact of failures on an emergency call system, considering service-level metrics such as the number of affected calls per failure and the time an emergency service takes until it recovers from a failure. We analyze a real data set from an emergency call center for a large Brazilian city. From stochastic models that represent a cloud data center, we evaluate different data center architectures to observe the impact of failures on the emergency call service. Results show that changing data center's architecture in order to improve availability from two to three nines cannot decrease the average number of affected calls per failure. On the other hand, it can decrease the probability to affect a considerable number of calls at the same time. KEYWORDS availability, cloud computing, data center failure, emergency call service 1 INTRODUCTION It is observed that reliability and availability analysis cannot accurately relate failures and user perception. For instance, a system with a 99.99% availability level is subject to about 52 minutes of downtime during a year. However, if the failure occurs during a peak hour, it has a higher impact on users' perception than a failure that occurs when the system load is low, as less users will be affected by it. According to Trivedi and Bobbio, 1 even short outages of technological infrastructures, such as cloud data centers, can have drastic consequences, ranging from economic loss to loss of human life. For instance, let us consider an emergency call service hosted in a cloud data center. The call center receives requests from patients, and depending on the case, an ambulance with a medical team can be dispatched to attend or to transport the patient to a hospital. This service relies on the cloud data center to be operational at all times and, consequently, to save lives. In order to guarantee a target availability level of a data center, different techniques can be applied to assess, predict, verify, and validate it. 1 Redundancy is the common mechanism used to achieve high availability. We therefore develop mathematical models, for instance, by using state-space methods to evaluate how redundancy techniques can improve the availability of a cloud service. In this paper, we use some previously proposed stochastic models to represent a cloud data center (see other works 2-4) and analyze how failures of such infrastructure impact an emergency call service. We evaluate different redundancy architectures following TIA-942, a standard that defines the recommended redundancy strategies and best practices to reach a specified availability level. In addition to availability-related metrics, we focus on service-level metrics such as the number of calls lost per failure in a year. To explore and study service-related metrics, we use real data provided by the Servico de Atendimento Móvel de Urgência (SAMU-Emergency Mobile Attendance Service), 5 a public emergency service offered by the Brazilian government to the general population. Our analysis is divided into two stages. Firstly, we present an overview of the SAMU's data in order to characterize and to detail it showing its relevance and overall behavior. These are measured in terms of the time between calls, attendance time, peak hours, and number of urgent
 Kishor S Trivedi
Kishor S Trivedi